The other week, I stumbled on the post
Inserting One Billion Rows in SQLite Under A Minute, which was a funny coincidence, as I was just in the process of giving my own SQLite/Objective-S
adapter a bit of tune-up. (The post's title later had "Towards" prepended, because the author wasn't close to hitting that goal).
This SQLite adapater was a spin-off of my earlier article series on optimizing JSON performance, itself triggered by
the ludicrously bad performance of Swift Coding at this rather simple and relevant task. To recap: Swift's JSON coder clocked in at about 10MB/s. By using
a streaming approach and a bit of tuning, we got that to around 200MB/s.
Since then, I have worked on making Objective-S much more useful for UI work, with the object-literal syntax making
defining UIs as convenient as the various "declarative" functional approaches such as React or SwiftUI. Except it is
still using the same AppKit or UIKit objects we know and love, and doesn't force us to embrace the silly notion that
the UI is a pure function of the model. Oh, and you get live previews that actually work. But more on that later.
So I am slowly inching towards doing a ToDoMVC, a benchmark that feels
rather natural to me. While I am still very partial to
just dumping JSON files, and the previous article series hopefully showed that this approach is plenty fast
enough, I realize that a lot of people prefer a "real" database, especially on the back-end, and I wanted to build that as well. One of the many benchmarks I have for Objective-S is that it should
be possible to build a nicer Rails with it. (At this point in time I am pretty sure I will hit that benchmark).
One of the ways to figure out if you have a good design is to stress-test it. One very useful stress-test is seeing
how fast it can go, because that will tell you if the thing you built is lean, or if you put in unnecessary layers
and indirections.
This is particularly interesting in a Scripted Components (pdf) system that combines a relatively slow
but flexible interactive scripting language with fast, optimized components. The question is whether you can actually
combine the flexibility of the scripting language while reaping the benefits of the fast components, rather than
having to dive into adapting and optimizing the components for each use case, or just getting slow performance despite
the fast components. My hunch was that the streaming approach I have been using for a while now and that worked really
well for JSON and Objective-C would also do well in this more challenging setting.
Spoiler alert: it did!
The benchmark
The benchmark was a slightly modified version of the script that serves as a tasks backend. Like said sample
script it also creates a tasks database and inserts some example rows. Instead of inserting two rows,
it inserts 10 million. Or a hundred million.
#!env stsh
#-taskbench:[dbref
#
class Task {
var id.
var done.
var title.
-description { "". }
+sqlForCreate {
'( [id] INTEGER PRIMARY KEY, [title] VARCHAR(220) NOT NULL, [done] INTEGER );'.
}
}.
scheme todo : MPWAbstractStore {
var db.
var tasksTable.
-initWithRef:ref {
this:db := (MPWStreamQLite alloc initWithPath:ref path).
this:tasksTable := #MPWSQLTable{ #db: this:db , #tableClass: Task, #name: 'tasks' }.
this:db open.
self.
}
-createTable {
this:tasksTable create.
this:tasksTable := this:db tables at:'tasks'.
this:tasksTable createEncoderMethodForClass: Task.
}
-createTaskListToInsert:log10ofSize {
baseList ← #( #Task{ #title: 'Clean Room', #done: false }, #Task{ #title: 'Check Twitter', #done: true } ).
...replicate ...
taskList.
}
-insertTasks {
taskList := self createTaskListToInsert:6.
1 to:10 do: {
this:tasksTable insert:taskList.
}.
}
}.
todo := todo alloc initWithRef:dbref.
todo createTable.
todo insertTasks.
]
(I have removed the body of the method that replicates the 2 tasks into the list of millions of tasks we need to insert.
It was bulky and not relevant.)
In this sample we define the Task class and use that to create the SQL Table. We could also have simply created
the table and generated a Tasks class from that.
Anyway, running this script yields the following result.
> time ./taskbench-sqlite.st /tmp/tasks1.db
./taskbench-sqlite.st /tmp/tasks1.db 4.07s user 0.20s system 98% cpu 4.328 total
> ls -al /tmp/tasks1.db*
-rw-r--r-- 1 marcel wheel 214M Jul 24 20:11 /tmp/tasks1.db
> sqlite3 /tmp/tasks1.db 'select count(id) from tasks;'
10000000
So we inserted 10M rows in 4.328 seconds, yielding several hundred megabytes of SQLite data. This would be 138M rows
had we let it run for a minute. Nice. For comparison, the original article's numbers were 11M rows/minute for
CPython, 40M rows/minute for PyPy and 181M rows/minute for Rust, though on a slower Intel MacBook
Pro whereas I was running this on an M1 Air. I compiled and ran the Rust version on my M1 Air and it did
100M rows in 21 seconds, so just a smidgen over twice as fast as my Objective-S script, though with
a simpler schema (CHAR(6) instead of VARCHAR(220)) and less data (1.5GB vs. 2.1GB for 100M rows).
Getting SQLite fast
The initial version of the script was far, far slower, and at first it was, er, "sub-optimal" use of SQLite
that was the main culprit, mostly inserting every row by itself without batching. When SQLite sees an
INSERT (or an UPDATE for that matter) that is not contained in a transaction, it will automatically wrap that
INSERT inside a generated transaction and commit that transaction after the INSERT is processed. Since
SQLite is very fastidious about ensuring that transactions get to disk atomically, this is slow. Very slow.
The class handling SQLite inserts is a Polymorphic Write Stream, so it knows what an array is.
When it encounters one, it sends itself the beginArray message, writes the contents of the array
and finishes by sending itself the endArray message. Since writing an array sort of implies that
you want to write all of it, this was a good place to insert the transactions:
-(void)beginArray {
sqlite3_step(begin_transaction);
sqlite3_reset(begin_transaction);
}
-(void)endArray {
sqlite3_step(end_transaction);
sqlite3_reset(end_transaction);
}
So now, if you want to write a bunch of objects as a single transaction, just write them as an array, as the
benchmark code does. There were some other minor issues, but after that less than 10% of the total time
were spent in SQLite, so it was time to optimize the caller, my code.
Column keys and Cocoa Strings
At this point, my guess was that the biggest remaining slowdown would be my, er, "majestic" Objective-S
interpreter. I was wrong, it was Cocoa string handling. Not only was I creating the SQLite parameter
placeholder keys dynamically, so allocating new NSString objects for each column of each row, it also
happens that getting character data from an NSString object nowadays involves some very complex and slow
internal machinery using encoding conversion streams.
-UTF8String is not your friend, and other
methods appear to fairly consistently use the same slow mechanism. I guess making NSString horribly slow is
one way to make other string handling look good in comparison.
After a few transformations, the code would just look up the incoming NSString key in a dictionary that
mapped it to the SQLite parameter index. String-processing and character accessing averted.
Jitting the encoder method. Without a JIT
One thing you might have noticed about the class definition in the benchmark code is that there is no
encoder method, it just defines its instance variables and some other utilities. So how is the class
data encoded for the
SQLTable? KVC? No, that would be a bit slow, though it might make a good
fallback.
The magic is the createEncoderMethodForClass: method. This method, as the name suggests,
creates an encoder method by pasting together a number of blocks, turns the top-level into
a method using imp_implementationWithBlock(), and then finally adds that method
to the class in question using class_addMethod().
-(void)createEncoderMethodForClass:(Class)theClass
{
NSArray *ivars=[theClass allIvarNames];
if ( [[ivars lastObject] hasPrefix:@"_"]) {
ivars=(NSArray*)[[ivars collect] substringFromIndex:1];
}
NSMutableArray *copiers=[[NSMutableArray arrayWithCapacity:ivars.count] retain];
for (NSString *ivar in ivars) {
MPWPropertyBinding *accessor=[[MPWPropertyBinding valueForName:ivar] retain];
[ivar retain];
[accessor bindToClass:theClass];
id objBlock=^(id object, MPWFlattenStream* stream){
[stream writeObject:[accessor valueForTarget:object] forKey:ivar];
};
id intBlock=^(id object, MPWFlattenStream* stream){
[stream writeInteger:[accessor integerValueForTarget:object] forKey:ivar];
};
int typeCode = [accessor typeCode];
if ( typeCode == 'i' || typeCode == 'q' || typeCode == 'l' || typeCode == 'B' ) {
[copiers addObject:Block_copy(intBlock)];
} else {
[copiers addObject:Block_copy(objBlock)];
}
}
void (^encoder)( id object, MPWFlattenStream *writer) = Block_copy( ^void(id object, MPWFlattenStream *writer) {
for ( id block in copiers ) {
void (^encodeIvar)(id object, MPWFlattenStream *writer)=block;
encodeIvar(object, writer);
}
});
void (^encoderMethod)( id blockself, MPWFlattenStream *writer) = ^void(id blockself, MPWFlattenStream *writer) {
[writer writeDictionaryLikeObject:blockself withContentBlock:encoder];
};
IMP encoderMethodImp = imp_implementationWithBlock(encoderMethod);
class_addMethod(theClass, [self streamWriterMessage], encoderMethodImp, "v@:@" );
}
What's kind of neat is that I didn't actually write that method for this particular use-case: I had
already created it for JSON-coding. Due to the fact that the JSON-encoder and the SQLite writer
are both Polymorphic Write Streams (as are the targets of the corresponding decoders/parsers),
the same method worked out of the box for both.
(It should be noted that this encoder-generator currently does not handle all variety of data types;
this is intentional).
Getting the data out of Objective-S objects
The encoder method uses
MPWPropertyBinding objects to efficiently access the instance
variables via the object's accessors, caching IMPs and converting data as necessary, so they are
both efficient and flexible. However, the actual accessors that Objective-S generated for its
instance variables were rather baroque, because they used the same basic mechanism used for
Objective-S methods, which can only deal with objects, not with primitive data types.
In order to interoperate seamlessly with Objective-C, which expected methods that can
take data types other than objects, all non-object method arguments are converted
to objects on the way in, and return values are converted from objects to primitive
values on the way out.
So even the accessors for primitive types such as the integer "id" or the boolean "done"
would have their values converted to and from objects by the interface machinery. As
I noted above, I was a bit surprised that this inefficiency was overshadowed by the
NSString-based key handling.
In fact, one of the reason for pursuing the SQLite insert benchmark was to have a
reason for finally tackling this Rube-Goldberg mechanism. In the end, actually
addressing it turned out to be far less complex than I had feared, with the technique
being very similar to that used for the encoder-generator above, just simpler.
Depending on the type, we use a different block that gets parameterised with the
offset to the instance variable. I show the setter-generator below, because
there the code for the object-case is actually different due to retain-count
handling:
#define pointerToVarInObject( type, anObject ,offset) ((type*)(((char*)anObject) + offset))
#ifndef __clang_analyzer__
// This leaks because we are installing into the runtime, can't remove after
-(void)installInClass:(Class)aClass
{
SEL aSelector=NSSelectorFromString([self objcMessageName]);
const char *typeCode=NULL;
int ivarOffset = (int)[ivarDef offset];
IMP getterImp=NULL;
switch ( ivarDef.objcTypeCode ) {
case 'd':
case '@':
typeCode = "v@:@";
void (^objectSetterBlock)(id object,id arg) = ^void(id object,id arg) {
id *p=pointerToVarInObject(id,object,ivarOffset);
if ( *p != arg ) {
[*p release];
[arg retain];
*p=arg;
}
};
getterImp=imp_implementationWithBlock(objectSetterBlock);
break;
case 'i':
case 'l':
case 'B':
typeCode = "v@:l";
void (^intSetterBlock)(id object,long arg) = ^void(id object,long arg) {
*pointerToVarInObject(long,object,ivarOffset)=arg;
};
getterImp=imp_implementationWithBlock(intSetterBlock);
break;
default:
[NSException raise:@"invalidtype" format:@"Don't know how to generate set accessor for type '%c'",ivarDef.objcTypeCode];
break;
}
if ( getterImp && typeCode ) {
class_addMethod(aClass, aSelector, getterImp, typeCode );
}
}
At this point, profiles were starting to approach around two thirds of the time being spent in
sqlite_ functions,
so the optimisation efforts were starting to get into a region of diminishing returns.
Linear scan beats dictionary
One final noticeable point of obvious overhead was the (string) key to parameter index mapping, which the
optimizations above had left at a
NSDictionary mapping from
NSString to
NSNumber.
As you probably know,
NSDictionary isn't exactly the fastest. One idea was to replace that lookup
with a
MPWFastrStringTable,
but that means either needing to solve the problem of fast access to
NSString character data or changing the
protocol.
So instead I decided to brute-force it: I store the actual pointers to the NSString objects in a C-Array indexed by
the SQLite parameter index. Before I do the other lookup, which I keep to be safe, I do a linear scan in that table
using the incoming string pointer. This little trick largely removed the parameter index lookup from my profiles.
Conclusion
With those final tweaks, the code is probably quite close to as fast as it is going to get. Its slower performance
compared to the Rust code can be attributed to the fact that it is dealing with more data and a more complex
schema, as well as having to actually obtain data from materialized objects, whereas the Rust code just generates
the SQlite calls on-the-fly.
All this is achieved from a slow, interpreted scripting language, with all the variable parts (data class, steering
code) defined in said slow scripting language. So while I look forward to the native compiler for Objective-S,
it is good to know that it isn't absolutely necessary for excellent performance, and that the basic design of
these APIs is sound.
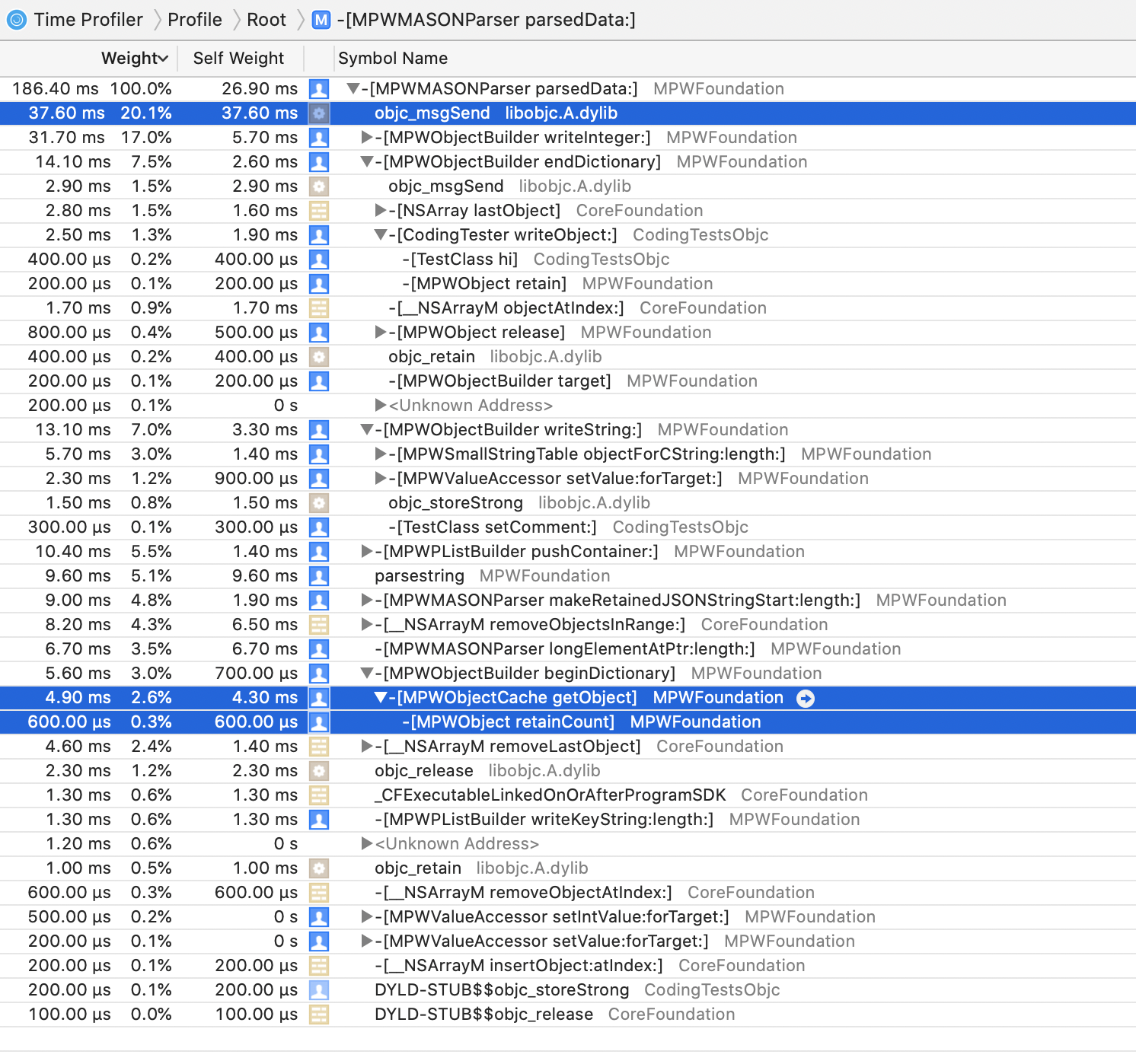
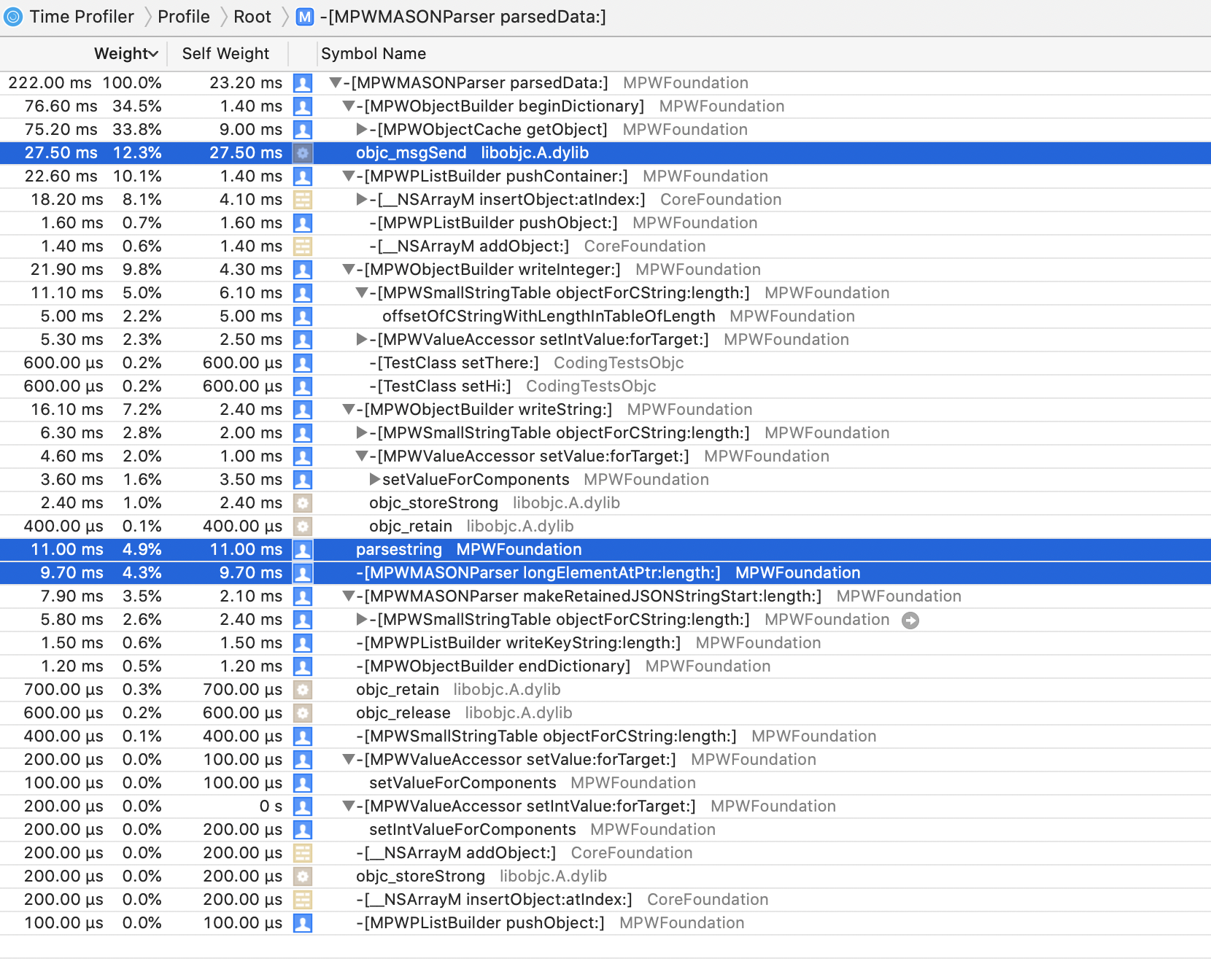
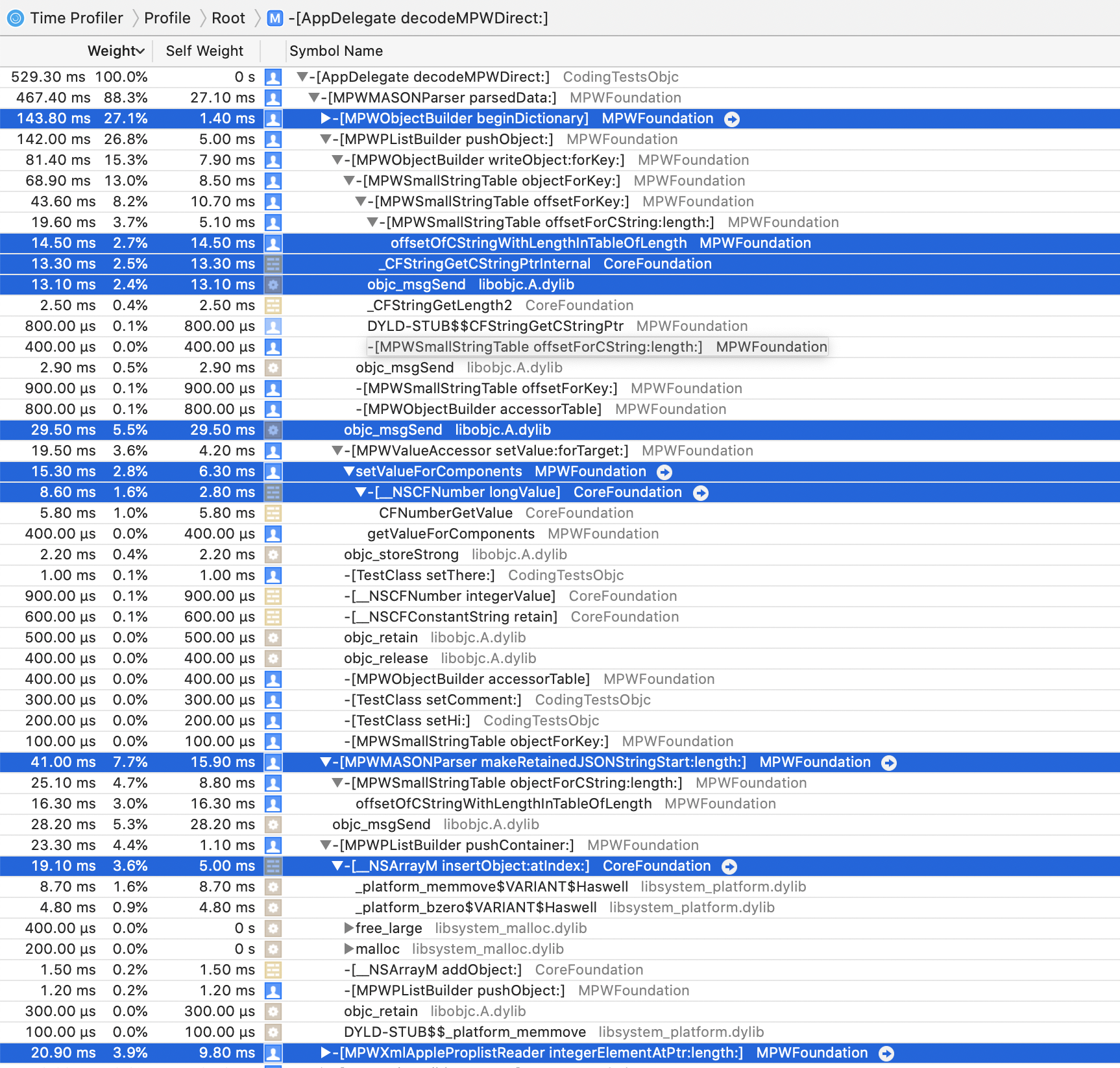
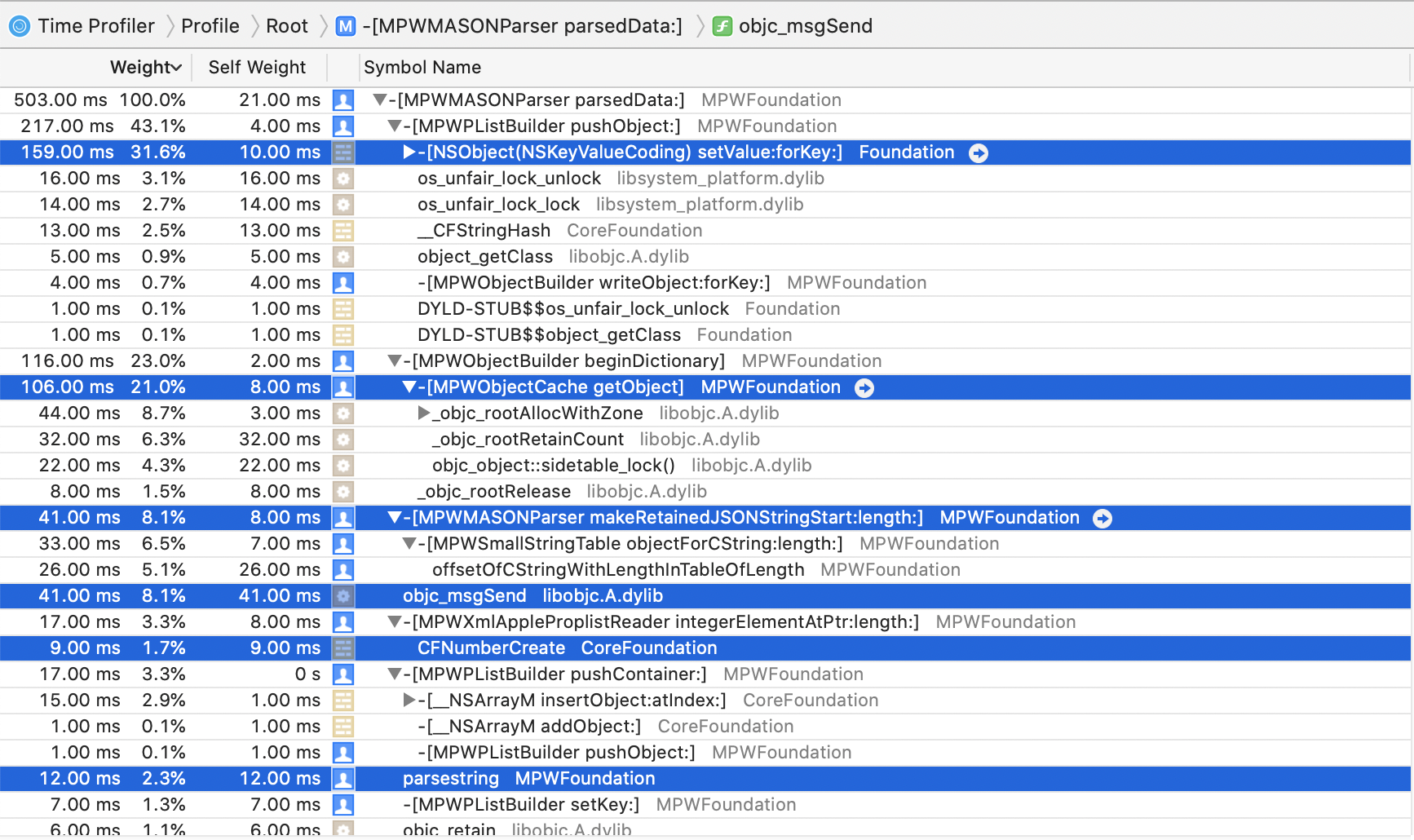
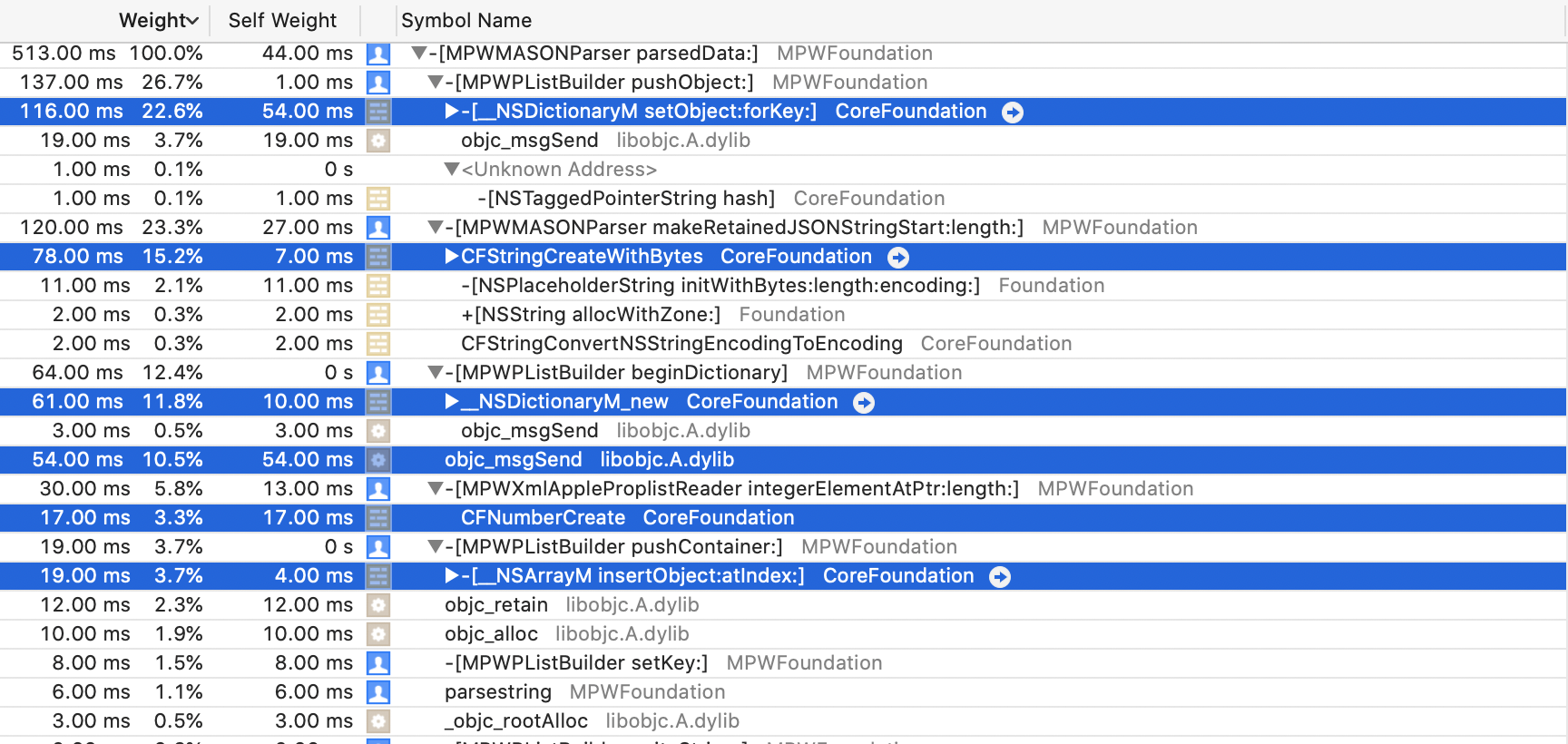 The top 4 consumers of CPU are
The top 4 consumers of CPU are 


