NSJSONSerialization, more or less, in the last instalment, with the
help of MPWSmallStringTable to unique our strings before turning them into
objects, string creation being surprisingly expensive even for tagged pointer strings.
Cutting out the Middleman: ObjectBuilder
In the first instalment of this series, we saw that we could fairly trivially create objects from the plist created byNSJSONSerialization.
MPWObjectBuilder (.h .m) is a subclass of MPWPlistBuilder that changes just
a few things: instead of creating dictionaries, it creates objects, and instead of using
-setObject:forKey: to set values in that dictionary, it uses the KVC message
-setValue:forKey: (vive la petite différence!) to set values in that object.
@implementation MPWObjectBuilder
-(instancetype)initWithClass:(Class)theClass
{
self=[super init];
self.cache=[MPWObjectCache cacheWithCapacity:20 class:theClass];
return self;
}
-(void)beginDictionary
{
[self pushContainer:GETOBJECT(_cache) ];
}
-(void)writeObject:anObject forKey:aKey
{
[*tos setValue:anObject forKey:aKey];
}
That's it! Well, all that need concern us for now, the actual class has some additional features that don't matter here. The
_tos instance variable is the top
of a stack that MPWPlistBuilder maintains while constructing the result.
The MPWObjectCache is just a factory for creating objects.So let's fire it up and see what it can do!
-(void)decodeMPWDirect:(NSData*)json
{
NSArray *keys=@[ @"hi", @"there", @"comment"];
MPWMASONParser *parser=[MPWMASONParser parser];
MPWObjectBuilder *builder=[[MPWObjectBuilder alloc] initWithClass:[TestClass class]];
[parser setBuilder:builder];
[parser setFrequentStrings:keys];
NSArray* objResult = [parser parsedData:json];
NSLog(@"MPWMASON %@ with %ld elements",[objResult firstObject],[objResult count]);
}
Not the most elegant code in the universe, and not a complete parser by an stretch of the imagination, but workable.
Result: 621 ms.
Not too shabby, only 50% slower than baseNSJSONSerialization on our non-representative 44MB JSON file,
but creating the final objects, instead of just the intermediate representation, and arround 7x faster than Apple's JSONDecoder.
Although still below 100 MB/s and nowhere near 2.5 GB/s we're also starting to close in on the performance level that should be achievable given the context, with 140ms for basic object creation and 124ms for a mostly empty parse.
Analysis and next steps
Ignoring such trivialities as actually being useful for more than the most constrained situations (array of single kind of object), how can we improve this? Well, make it faster, of course, so let's have a look at the profile:
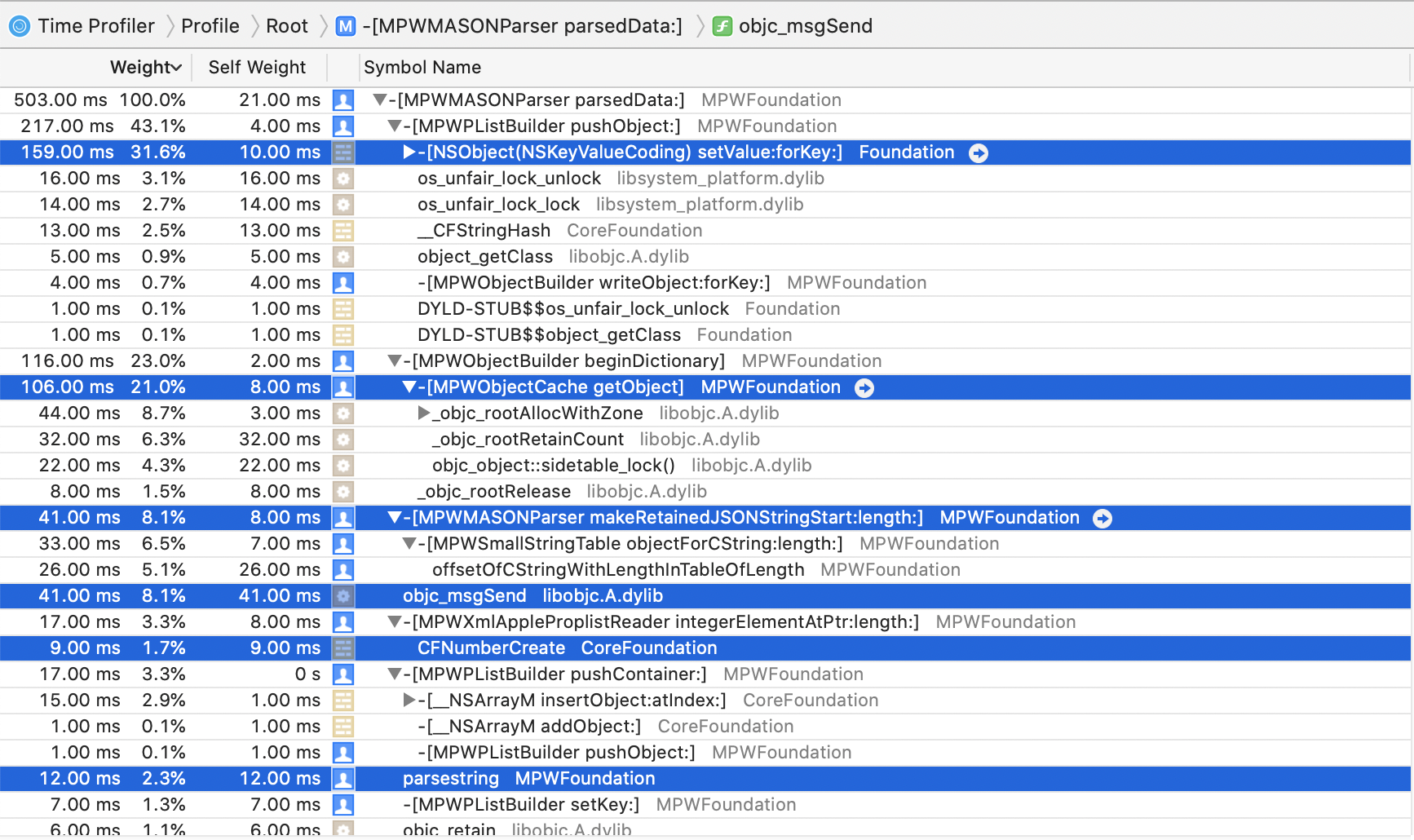
As expected, the KVC code is now the top contributor, with around 40% of total runtime.
(The locking functions that show up as siblings of -setValue:forKey: are almost
certainly part of that implementation, this slight misattribution of times is something you
should generally expect and be aware of with Instruments. I am guessing it has to do with missing frame-pointers
(-fomit-frame-pointer) but don't really feel any deep urge to investigate, as it doesn't
materially impact the outcome of the analysis.
I guess that's another point: gather enough data to inform your next step, certainly no less, but also no more. I see both mistakes, the more common one definitely being making things "fast" without enough data. Or any, for that matter. If I had a €uro for every project that claims high performance without any (comparative) benchmarking, simply because they did something the authors think should be fast, well, you know, ....
The other extreme is both less common and typically less bad, as at least you don't get the complete nonsense of performance claims not backed by any performance testing, but running a huge battery of benchmarks on every step of an optimization process is probably going to get in the way of achieving results, and yes, I've seen this in practice.
So next we need to remove KVC.
TOC
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 1: The Status QuoSomewhat Less Lethargic JSON Support for iOS/macOS, Part 2: Analysis
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 3: Dematerialization
Equally Lethargic JSON Support for iOS/macOS, Part 4: Our Keys are Small but Legion
Less Lethargic JSON Support for iOS/macOS, Part 5: Cutting out the Middleman
Somewhat Faster JSON Support for iOS/macOS, Part 6: Cutting KVC out of the Loop
Faster JSON Support for iOS/macOS, Part 7: Polishing the Parser
Faster JSON Support for iOS/macOS, Part 8: Dematerialize All the Things!
Beyond Faster JSON Support for iOS/macOS, Part 9: CSV and SQLite

4 comments:
maybe slightly off-topic, but...
are you saying that swifts JSONDecoder is actually slower than NSJSONSerialization?
if so, wow...didnt expect that
Not off-topic at all, and yes, JSONDecoder is slower than NSJSONSerialization. And not just by a little bit: it is almost an order of magnitude slower!
With the current implementation of JSONDecoder, being at least somewhat slower than NSJSONSerialization is inevitable, as JSONDecoder is based on NSJSONSerialization, so it first calls NSJSONSerialization to actually parse the JSON to a plist and then decodes from the resulting plist.
So you're never going to be faster overall, at least not with the current implementation. However, you could reasonably expect the extra processing going from the plist that NSJSONSerialization produces to Swift structs/objects to be faster than the original parse and plist creation. But that is also not the case, the time spent in Swift coding is several times that spent in NSJSONSerialization.
thanks for the reply!
> But that is also not the case, the time spent in Swift coding is several times that spent in NSJSONSerialization.
does this seem like a fundamental limtation (flaw?) at the api level?
in other words, the only way to speed up Codable would be to redesign it?
(sorry if those questions are/will be answered in your articles... didnt see it yet)
I don't know if this is fixable with the current API or requires a redesign. The empirical evidence so far is not looking good, but it needs a more detailed answer which I am hoping to provide in a future article.
Post a Comment