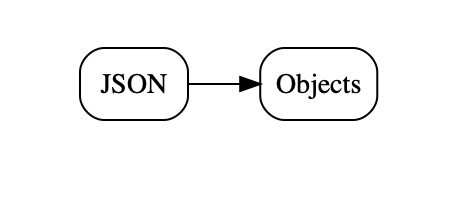
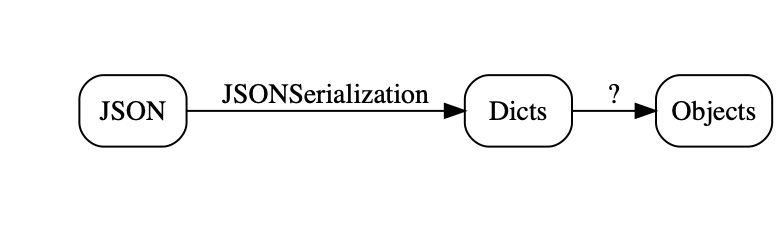
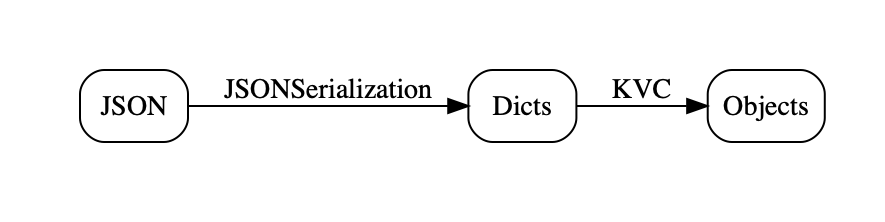
JSONDecoder. At this point, creating the objects and adding them to
the array take a combined total of 45%, and surely this is something we can't reasonably get rid off.
Is it?
Object Streaming
Although the requirement was for objects to be created, nobody said that they all have to exist at the same time. Instead of returning the complete array of parsed objects when done, we can also tell the parser to stream objects to some target as they come in, by setting thestreamingThreshold, which says at which depth into the JSON tree we start
to use streaming.
-(void)decodeMPWDirectStream:(NSData*)json
{
MPWMASONParser *parser=[[MPWMASONParser alloc] initWithClass:[TestClass class]];
MPWObjectBuilder *builder=(MPWObjectBuilder*)[parser builder];
[builder setStreamingThreshold:1];
[builder setTarget:self];
[parser parsedData:json];
}
Since we've set ourselves as the streaming target we need to provide a
writeObject:
method in order to conform to the Streaming protocol.
-(void)writeObject:(TestClass*)anObject
{
if (!first) {
first=[MPWRusage current];
}
objCount++;
hiCount+=anObject.hi;
}
This method counts the objects and sums up their
hi instance variables. It also
records the time the first object comes in. How does this do?Very well, at 192 ms and 229 MB/s. In addition, the time to first object is around 700 µs, so less than a millisecond for an application to start receiving usable data and be able to provide feedback to the user.
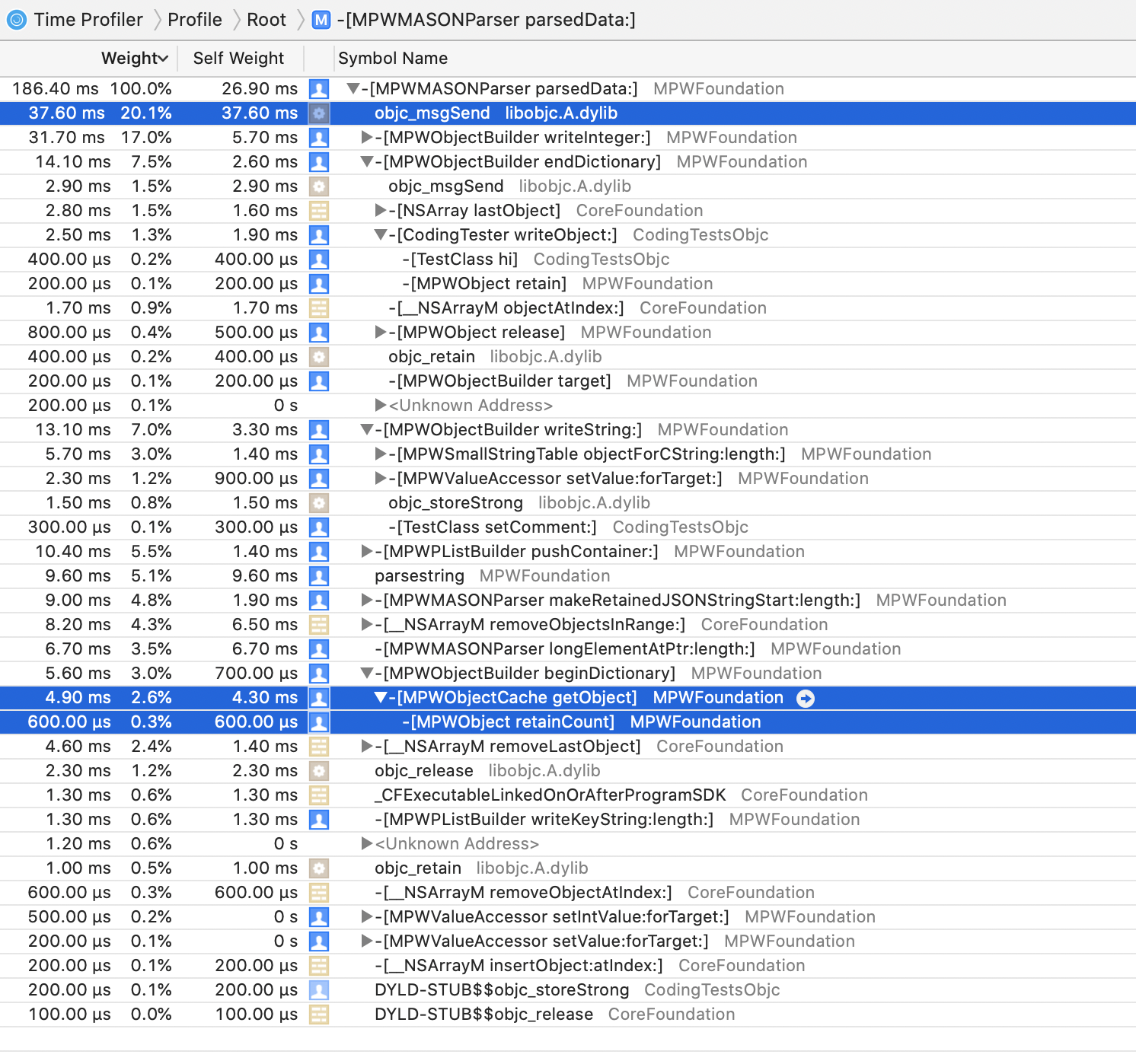
What's immediately noticeable is that the beginDictionary method is no longer at the top of the profile,
it is almost all the way to the bottom with just 2.6% and 4.3ms of the total running time.
How is this actually possible? After all, we still get the 1 million objects, so we still have to create all of them, even if we dole them out in a piecemeal fashion. Or do we?
MPWObjectCache
The MPWObjectCache class (.h .m), keeps a circular buffer of objects that it can reinitialize and reuse after the application code is done with them. It is described in some detail in my book (did I mention the book?), in a part that Pearson has kindly made publicly available.With such a cache in place, we only actually instantiate the number of objects needed to fill the cache, after that we safely recycle those same objects over and over again, at the cost of a few function calls. If objects are retained, they will not be reused.
Column stores, or structures of arrays
Another neat way of interpreting dematerialization is to store all the data in a columnar data format, a structure of arrays (SoA) instead of Array of Structures (AoS) organisation. (Thanks to Holgi for suggesting this).For this we need a specific builder (MPWArraysBuilder, .h .m) that maintains a set of (mutable) arrays stored by key. When it receives a value, it looks up the appropriate array by key and adds the value to that array, as follows:
-(void)writeInteger:(long)number
{
if ( _arrayMap && keyStr) {
MPWIntArray *a=OBJECTFORSTRINGLENGTH(_arrayMap, keyStr, keyLen);
[a addInteger:(int)number];
keyStr=NULL;
}
}
-(void)writeString:(id)aString
{
if ( _arrayMap && keyStr) {
NSMutableArray *a=OBJECTFORSTRINGLENGTH(_arrayMap, keyStr, keyLen);
[a addObject:aString];
keyStr=NULL;
}
}
For integer values, this would be an
MPWIntArray (.h .m) for strings a regular
NSMutableArray. This does even better, at 155 ms / 284 MB/s.
Other options
These are not the only options. For example, it turns out that the protocol connecting parser and builder was not specifically created for this purpose, it actually extends theStreaming
protocol to handle disassembled hierarchies. So you can take a tree, pipe it
through a pipeline and then accurately reassemble it on the other end.The protocol is used in Polymorphic Write Streams to enable Standard Object Out shown at DLS '19, with an earlier version presented at Macoun 2018 (German):
Outlook
However, we are probably hitting diminishing returns at this point, certainly for a proof of concept. There is certainly some more fat to trim, someobjc_msgSend()s to IMP-cache away, and
going over most of the character input twice is probably something we could avoid.Apart from further performance improvements, there are also minor details of correctness to take care of, for example handling the JSON escape characters in keys or properly handling hierarchy. These things are not particularly hard, and are handled for XML in the superclass, but do require a bit of thought and effort to complete.
There is also the question of hooking up to Swift in general (a simple attempt failed in
getting the right methods), or Codable in particular. The latter would require
a somewhat different approach from now: instead of instantiating the object and actively
setting its properties, you need to create a temporary structure that you then pass to
the object's decoder so it can decode itself. Again, the MAX superclass uses this approach,
so it probably won't be too hard to do, with the main trickiness probably in reconciling
that more hierarchical/recursive approach with the streaming required by the protocol.
I can (and probably will) also go into a little more analysis of the hows and whys of this approach. So maybe provide some feedback: what would interest you most? Are you interested in a production version of this? Or more extreme optimizations (the ones so far were fairly tame)?
Note
I can help not just Apple, but also you and your company/team with performance and agile coaching, workshops and consulting. Contact me at info at metaobject.com.TOC
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 1: The Status QuoSomewhat Less Lethargic JSON Support for iOS/macOS, Part 2: Analysis
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 3: Dematerialization
Equally Lethargic JSON Support for iOS/macOS, Part 4: Our Keys are Small but Legion
Less Lethargic JSON Support for iOS/macOS, Part 5: Cutting out the Middleman
Somewhat Faster JSON Support for iOS/macOS, Part 6: Cutting KVC out of the Loop
Faster JSON Support for iOS/macOS, Part 7: Polishing the Parser
Faster JSON Support for iOS/macOS, Part 8: Dematerialize All the Things!
Beyond Faster JSON Support for iOS/macOS, Part 9: CSV and SQLite
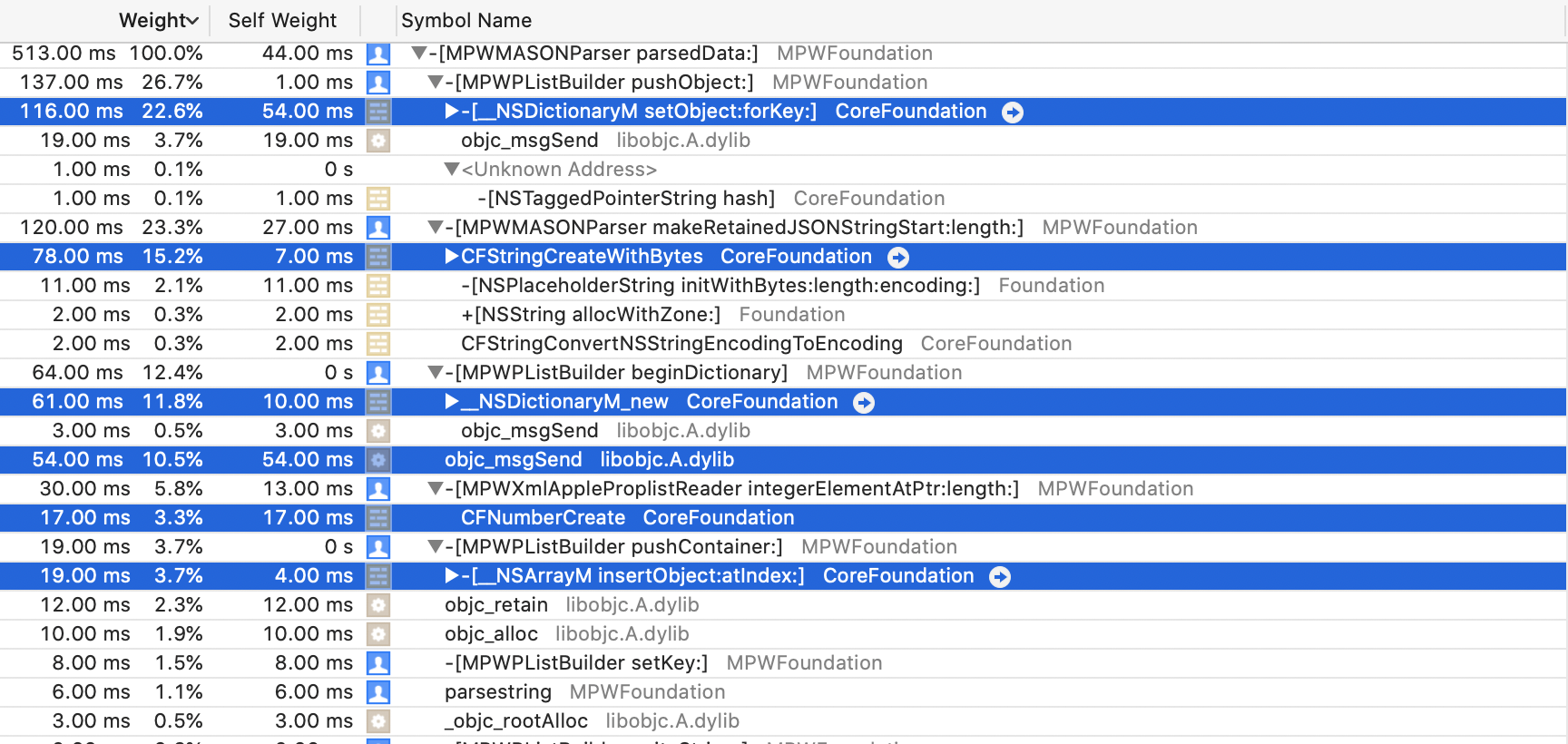 The top 4 consumers of CPU are
The top 4 consumers of CPU are