A convenient setback
One thing that you may have noticed last time around was that we were getting the instance variable names from the class, but then also still manually setting the common keys manually. That's a bit of duplicated and needlessly manual effort, because the common keys are exactly those ivar names.However, the two pieces of information are in different places, the ivar names in the builder and the common strings in the in the parse itself. One way of consolidating this information is by creating a convenience intializer for decoding to objects as follows:
-initWithClass:(Class)classToDecode
{
self = [self initWithBuilder:[[[MPWObjectBuilder alloc] initWithClass:classToDecode] autorelease]];
[self setFrequentStrings:(NSArray*)[[[classToDecode ivarNames] collect] substringFromIndex:1]];
return self;
}
We still compute the ivar names twice, but that's not really such a big deal, so something we can fix later, just like the issue that we should probably be using property names instead of instance variable names that in the case of properties we have to post-process to get rid of the underscores added by ivar synthesis.
With that, the code to parse to objects simplifies to the following, very
similar to what you would see in Swift with JSONDecoder.
-(void)decodeMPWDirect:(NSData*)json
{
MPWMASONParser *parser=[[MPWMASONParser alloc] initWithClass:[TestClass class]];
NSArray* objResult = [parser parsedData:json];
}
So, quickly verifying that performance is still the same (always do this!) and...oops! Performance dropped significantly, from 441ms to over 700ms. How could such an innocuous change lead to a 50% performance regression?
The profile shows that we are now spending significantly more time in
A little further sleuthing revealed that the strings in question are now instances of
This isn't really easy to solve, since the creation of
Where previously the builder had a
The results are encouraging: 299ms, or 147 MB/s.
The
Changing that, initially just for integers, is straightforward: add an integer-valued
message to the builder protocol and implement it.
Together with using direct instance variable access instead of properties to get to
the accessorTable, this yields a very noticeable speed boost:
229 ms, or 195 MB/s.
Nice.
Although there is obviously some truth in that, profiles were used and more C primitive types appeared,
I would contend that what happened was a move away from objects, and particularly away from generic
and expensive Foundation objects ("Foundation oriented programming"?) towards
message oriented programming.
The big idea is "messaging" -- that is what the kernal of Smalltalk/Squeak
is all about (and it's something that was never quite completed in our
Xerox PARC phase). The Japanese have a small word -- ma -- for "that which
is in between" -- perhaps the nearest English equivalent is "interstitial".
The key in making great and growable systems is much more to design how its
modules communicate rather than what their internal properties and
behaviors should be.
The combination of objects + primitive messages is very similar
to another architecturally elegant and productive style: Unix
pipes and filters. The components are in C and can have as rich
an internal structure as you want, but they have to talk to each
other via byte-streams. This can also be made very fast, and
also prevents or at least reduces coupling between the components.
Another aspect is the tension between an API for use and an
API for reuse, particularly within the constraints of call/return.
When you get tasked with "Create a component + API for parsing JSON", something
like
Anyway, let's look at the current profile:
First, times are now small enough that high-resolution (100µs) sampling is now necessary to get meaningful results.
Second, the
With the work we've done so far, we've improved speed around 5x from where we started, and at 195 MB/s are almost
20x faster than Swift's
Can we do better? Stay tuned.
objectForKey: method, where it gets the bytes out of the NSString/CFString,
but why that should be the case is a bit mysterious, since we changed virtually nothing.NSTaggedPointerString,
where previously they were instances of __NSCFConstantString. The latter has a pointer to its
byte-oriented character orientation, which it can simply return, while the former cleverly encodes the
characters in the pointer itself, so it first has to reconstruct that byte representation. The method
of constructing that representation and computing the size of such a representation also appears to be
fairly generic and slow via a stream.NSTaggedPointerStrring instances
is hardwired pretty deep in CoreFoundation with no way to disable this "optimization". Although it would
be possible to create a new NSString subclass with a byte buffer,
make sure to convert to that class before putting instances in the lookup table, that seems like
a lot of work. Or we could just revert this convenience.Damn the torpedoes and full speed ahead!
Alternatively, we really wanted to get rid of this whole process of packing character data
into NSString instances just to immediately unpack them again, so let's
leave the regression as is and do that instead.NSString *key instance vaiable, it now has
a char *keyStr and a int keyLen. The string-handling case
in the JSON parser is now split betweeen the key and the non-key casse, with the non-key
case still doing the conversion, but the key-case directly sending the char*
and length to the builder.
case '"':
parsestring( curptr , endptr, &stringstart, &curptr );
if ( curptr[1] == ':' ) {
[_builder writeKeyString:stringstart length:curptr-stringstart];
curptr++;
} else {
curstr = [self makeRetainedJSONStringStart:stringstart length:curptr-stringstart];
[_builder writeString:curstr];
}
curptr++;
break;
This means that at least temporarily, JSON escape handling is disabled for keys. It's straightforward
to add back, makeRetainedJSONStringStart:length: does all its processing in a character
buffer, only converting to a string object at the very end.
-(void)writeString:(NSString*)aString
{
if ( keyStr ) {
MPWValueAccessor *accesssor=OBJECTFORSTRINGLENGTH(self.accessorTable, keyStr, keyLen);
[accesssor setValue:aString forTarget:*tos];
keyStr=NULL;
} else {
[self pushObject:aString];
}
}
If there is a key, we are in a dictionary, otherwise an array (or top-level). In the dictionary
case, we can now fetch the ValueAccessor via the OBJECTFORSTRINGLENGTH()
macro. MPWPlistBuilder also needs to be adjusted: as it builds and NSDictionary
and not an object, it actually needs the NSString key, but the parser no longer
delivers those. So it just creates them on the fly:
-(NSString*)key
{
NSString *key=nil;
if ( keyStr) {
if ( _commonStrings ) {
key=OBJECTFORSTRINGLENGTH(_commonStrings, keyStr, keyLen);
}
if ( !key ) {
key=[[[NSString alloc] initWithBytes:keyStr length:keyLen encoding:NSUTF8StringEncoding] autorelease];
}
}
return key;
}
Surprisingly, this makes the dictionary parsing code slightly faster, bringing up to par with
NSSJSSONSerialization at 421ms.Eliminating NSNumber
Our use of NSNumber/CFNumber values is very similar to our use of
NSString for keys: the parser wraps the parsed number in the object, the
builder then unwraps it again.
-(void)writeInteger:(long)number
{
if ( keyStr ) {
MPWValueAccessor *accesssor=OBJECTFORSTRINGLENGTH(_accessorTable, keyStr, keyLen);
[accesssor setIntValue:number forTarget:*tos];
keyStr=NULL;
} else {
[self pushObject:@(number)];
}
}
The actual integer parsing code is not in MPWMASONParser but its superclasss, and as we don't
want to touch that for now, let's just copy-paste that code, modifying it to return a C primitive type
instead of an object.
-(long)longElementAtPtr:(const char*)start length:(long)len
{
long val=0;
int sign=1;
const char *end=start+len;
if ( start[0] =='-' ) {
sign=-1;
start++;
} else if ( start[0]=='+' ) {
start++;
}
while ( start < end && isdigit(*start)) {
val=val*10+ (*start)-'0';
start++;
}
val*=sign;
return val;
}
I am sure there are better ways to turn a string into an int, but it will do for now.
Similarly to the key/string distinction, we now special case integers.
if ( isReal) {
number = [self realElement:numstart length:curptr-numstart];
[_builder writeString:number];
} else {
long n=[self longElementAtPtr:numstart length:curptr-numstart];
[_builder writeInteger:n];
}
Again, not pretty, but we can clean it up later.Discussion
What happened here? Just random hacking on the profile and replacing nice object-oriented programming
with ugly but fast C?
I'm sorry that I long ago coined the
term "objects" for this topic because it gets many people to focus on the
lesser idea.
It turns out that message oriented programming (or should we call it
Protocol Oriented Programming?)
is where Objective-C shines: coarse-grained objects, implemented
in C, that exchange messages, with the messages also as primitive
as you can get away with. That was the idea, and when you
follow that idea, Objective-C just hums, you get not just
fast, but also flexible and architecturally nicely decoupled objects: elegance.NSJSONSerialization is something you almost have to
come up with: feed it JSON, out comes parsed JSON. Nothing could be
more convenient to use for "parsing JSON".MPWMASONParser on the other hand is not convenient at all
when viewed in isolation, but it's much more capable of being smoothly
integrated into a larger processing chain. And most of the work that
NSJSONSerialization did in the name of convenience is
now just wasted, it doesn't make further processing any easier but
sucks up enormous amounts of time.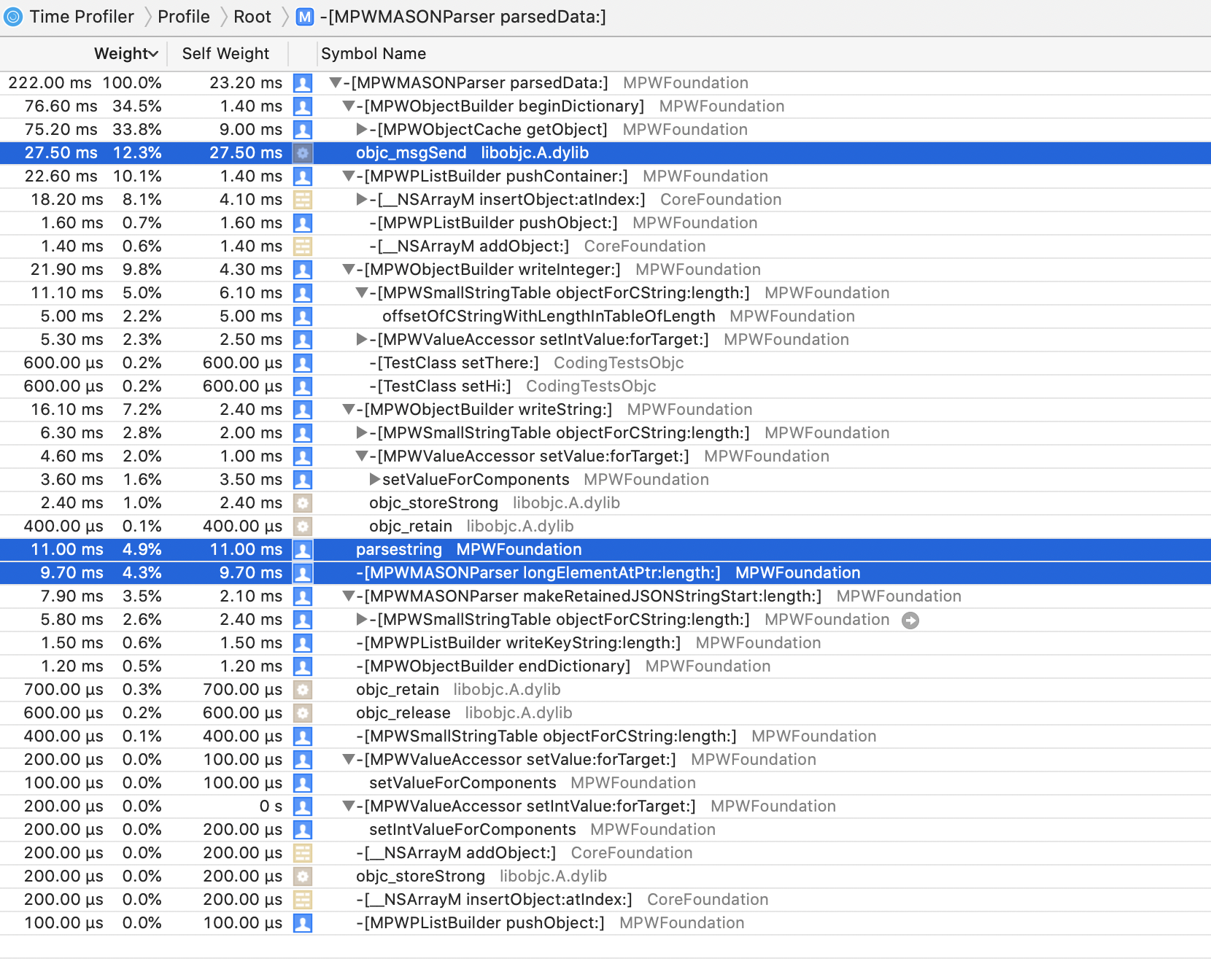
NSNumber/CFNumber and NSString packing and unpacking is gone,
with an even bigger chunk of the remaining time now going to object creation. objc_msgSend() is now starting to
actually become noticeable, as is the (inefficient) character level parsing. The accessors of our test objects
start to appear, if barely.JSONDecoder.Note
I can help not just Apple, but also you and your company/team with performance and agile coaching, workshops and consulting.
Contact me at info at metaobject.com.
TOC
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 1: The Status Quo
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 2: Analysis
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 3: Dematerialization
Equally Lethargic JSON Support for iOS/macOS, Part 4: Our Keys are Small but Legion
Less Lethargic JSON Support for iOS/macOS, Part 5: Cutting out the Middleman
Somewhat Faster JSON Support for iOS/macOS, Part 6: Cutting KVC out of the Loop
Faster JSON Support for iOS/macOS, Part 7: Polishing the Parser
Faster JSON Support for iOS/macOS, Part 8: Dematerialize All the Things!
Beyond Faster JSON Support for iOS/macOS, Part 9: CSV and SQLite

No comments:
Post a Comment