This reminded me of a recent twitter conversation where I had offered to contribute a fast, Swift-compatible JSON parser loosely based on MAX, my fast and convenient XML parser. Due to various factors most of which are not under my control, I can't really offer anything that's fast when compared to simdjson, but I can manage something quite a bit less lethargic than what's currently on offer in the Apple and particularly the Swift world.
Environmental assumptions and constraints
My first assumption is that we are going to operate in the Apple ecosystem, and for simplicity's sake I am going to use macOS. Next, I will assume that what we want from our parse(r) are domain objects for further processing within our application (or structs, the difference is not important in this context).
We are going to use the following class with a mix of integer and string instance variables, in Swift:
@objc class TestClass: NSObject, Codable {
let hi:Int
let there:Int
let comment:String
...
}
and the same in Objective-C:
@interface TestClass : NSObject
@property (nonatomic) long hi,there;
@property (nonatomic,strong) NSString *comment;
@end
To make it all easy to measure, we are going to use one million objects, which we are going to initialise with increasing integers and the constant string
"comment". This yields the same 44MB JSON file with different serialisation methods, which can be correctly parsed by all the parsers tested. This is obviously a very simple class an file structure, but I think it gives a reasonable approximation for real-world use.The first thing to check is how quickly we can create these objects straight in code, without any parsing.
That should give us a good upper bound for the performance we can achieve when parsing to domain objects.
#define COUNT 1000000
-(void)createObjects
{
NSMutableArray *objResult=[NSMutableArray arrayWithCapacity:COUNT+20];
for ( int i=0;i<COUNT;i++ ) {
TestClass *cur=[TestClass new];
cur.hi=i;
cur.there=i;
cur.comment=@"comment";
[objResult addObject:cur];
}
NSLog(@"Created objects in code w/o parsing %@ with %ld objects",objResult[0],[objResult count]);
}
On my Quad Core, 2.7Ghz MBP '18, this runs in 0.141 seconds. Although we aren't actually parsing, it would mean that just creating all the objects that would result from parsingg our 44MB JSON file would yield a rate of 312 MB/s.
Wait a second! 312MB/s is almost 10x slower than Daniel Lemire's parser, the one that actually parses JSON, and we are only creating the objects that would result if we were parsing, without doing any actual parsing.
This is one of the many unintuitive aspects of parsing performance: the actual low-level, character-level parsing is generally the
least important part for overall performance. Unless you do something crazy like use NSScanner. Don't use NSScanner. Please.
One reason this is unintuitive is that we all learned that performance is dominated by the innermost loop, and character level processing is the innermost loop. But when you have magnitudes in performance differences and inner and outer loops differ by less than that amount, the stuff happennnig in the outer loop can dominate.
NSJSONSerialization
Apple's JSON story very much revolves aroundNSJSONSerialization, very much like most of the rest of
its serialization story revolves around the very similar NSPropertyListSerialization class. It has
a reasonable quick implementation, turning the 44 MB JSON file into an NSArrray of NSDictionary
instances in 0.421 seconds when called from Objective-C, for a rate of 105 MB/s. From Swift, it takes 0.562 seconds, for 78 MB/s.Of course, that gets us to a property list (array of dicts, in this case), not to the domain objects we actually want.
If you read my book (did I mention my book? Oh, I think I did), you will know that this type of dictonary representation is fairly expensive: expensive to create, expensive in terms of memory consumption and expensive to access. Just creating dictionaries equivalent to the objects we created before takes 0.321 seconds, so around 2.5x the time for creating the equivalent objects and a "rate" of 137 MB/s relative to our 44 MB JSON file.
-(void)createDicts
{
NSMutableArray *objResult=[NSMutableArray arrayWithCapacity:COUNT+20];
for ( int i=0;i<COUNT;i++ ) {
NSMutableDictionary *cur=[NSMutableDictionary dictionary];
cur[@"hi"]=@(i);
cur[@"there"]=@(i);
cur[@"comment"]=@"comment";
[objResult addObject:cur];
}
NSLog(@"Created dicts in code w/o parsing %@ with %ld objects",objResult[0],[objResult count]);
}
Creating the dict in a single step using a dictionary literal is not significantly faster, but creating an immutable copy of the mutable dict after we're done filling brings the time to half a second.
Getting from dicts to objects is typically straightforward, if tedious: just fetch the entry of the dictionary and call the corresponding setter with the value thus retrieved from the dictionary. As this isn't production code and we're just trying to get some bounds of what is possible, there is an easier way: just use Key Value Coding with the keys found in the dictionary. The combined code, parsing and then creating the objects is shown below:
-(void)decodeNSJSONAndKVC:(NSData*)json
{
NSArray *keys=@[ @"hi", @"there", @"comment"];
NSArray *plistResult=[NSJSONSerialization JSONObjectWithData:json options:0 error:nil];
NSMutableArray *objResult=[NSMutableArray arrayWithCapacity:plistResult.count+20];
for ( NSDictionary *d in plistResult) {
TestClass *cur=[TestClass new];
for (NSString *key in keys) {
[cur setValue:d[key] forKey:key];
}
[objResult addObject:cur];
}
NSLog(@"NSJSON+KVC %@ with %ld objects",objResult[0],[objResult count]);
}
Note that KVC is slow. Really slow. Order-of-magnitude slower than just sending messages kind of slow, and so it has significant impact on the total time, which comes to a total of 1.142 seconds including parsing and object creation, or just shy of 38 MB/s.
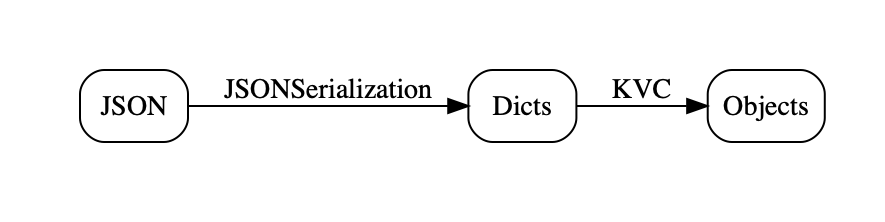
Swift JSON Coding
For the first couple of releases of Swift, JSON support by Apple was limited to a wrappedNSJSONSerialization, with the slight
performance penalty already noted. As I write in my book (see sidebar), many JSON "parsers" were published, but none of these
with the notable exception of the Big Nerd Ranch's Freddy were actual parses, they all just transformed the
arrays and dictionaries returned by NSJSONSerialization into Swift objects. Performance was
abysmal, with around 25x overhead in addition to the basic NSJSONSerialization parse.
Apple's Swift Codable promised to solve all that, and on the convenience front it certainly does
a great job.
func readJSONCoder(data:Data) -> [TestClass] {
NSLog("Swift Decoding")
let coder=JSONDecoder( )
let array=try! coder.decode([TestClass].self, from: data)
return array
}
(All the forcing is because this is just test code, please don't do this in production!). Alas, performance is still not great: 4.39 seconds, or 10 MB/s. That's 10x slower than the basic
NSJSONSerialization
parse and 4x slower than our slow but simple complete parse via NSJSONSerialization and KVC.However, it is significantly faster than the previous third-party JSON to Swift objects "parsers", to the tune of 3-4x. This is the old "first mark up 400% then discount 50%" sales trick applied to performance, except that the relative numbers are larger.
Third Party JSON Parsers
I looked a little at third party JSON parsers, particularly JASON, STJSON and ZippyJSON.
STTJSON does not make any claims to speed and manages to clock in at 5 seconds, or just under 10 MB/s. JASON bills
itself as a "faster" JSON parser (they compare to SwiftyJSON), and does reasonably well at 0.75 seconds or 59 MB/s.
However both of these parse to their own internal representation, not to domain objects (or structs), and so should
be compared to NSJSONSerialization, at which point they both disappoint.
Probably the most interesting of these is ZippyJSON, as it uses Daniel Lemire's simdjson and is Codable
compatible. Alas, I couldn't get ZippyJSON to compile, so I don't
have numbers, but I will keep trying. They claim around 3x faster than Apple's JSONDecoder, which
would make it the only parser to be at least in the same ballpark as the trivial NSJSONSerialization + KVC method I showed above.
Another interesting tidbit comes from ZippyJSON's README, under the heading "Why is it so much faster".
Apple's version first converts the JSON into an NSDictionary using NSJSONSerialization and then afterwards makes things Swifty. The creation of that intermediate dictionary is expensive.
This is true by itself: first converting to an intermediate representation is slow, particularly one
that's as heavy-weight as property lists. However, it cannot be the primary reason, because creating that
expensive representation only takes 1/8th of the total running time. The other 7/8ths is Codable apparently
talking to itself. And speaking very s-l-o-w-l-y while doing that.
To corroborate, I also tried a the Flight-School implementation of Codable for MessagePack, which obviously does not use NSJSONSerialization.
It makes no performance claims and takes 18 seconds to decode the same
objects we used in the JSON files, of course with a different file that's 34 MB in size. Normalized to our 44 MB
file that would be 2.4 MB/s.
MAX and MASON
So where does that leave us? Considering what simdjs shows is theoretically possible with JSON parsing, we are not in a good place, to put it mildly. 2.5 GB/s vs. 10 MB/s with Apple's JSONDecoder, several times slower thanNSJSONSerialization, which isn't exactly a speed daemon and around 30x slower than pure object creation. Comically bad might be another way of putting it. At least we're being entertained. What can I contribute? Well, I've been through most of this once before with XML and the result was/is MAX (Messaging API for XML), a parser that is not just super-fast itself (though no SIMD), but also presents APIs that make it both super-convenient and also super-fast to go directly from the XML to an object-representation, either as a tree or a stream of domain objects while using mostly constant memory. Have I mentioned my book? Yeah, it's in the book, in gory detail.
Anyway, XML has sorta faded, so the question was whether the same techniques would work for a JSON parser. The answer is yes, roughly, though with some added complexity and less convenience because JSON is a less informative file format than XML. Open- and close-tags really give you a good heads-up as to what's coming that "{" just does not.
The goal will be to produce domain objects at as close to the theoretical maximum of slightly more than 300 MB/s as possible, while at the same time making the parser convenient to use, close to Swift Codable in convenience. It won't support Codable per default, as the overheads seem to be too high, but ZippyJSON suggests that an adapter wouldn't be too hard.
That parser is MPWMASONParser,
and no, it isn't done yet. In its initial state, it parses JSON to dictionaries in 0.58 seconds, or 76 MB/s and
slightly slower than NSJSONSerialization.
So we have a bit of way to go, come join me on this little parsing performance journey!
TOC
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 1: The Status QuoSomewhat Less Lethargic JSON Support for iOS/macOS, Part 2: Analysis
Somewhat Less Lethargic JSON Support for iOS/macOS, Part 3: Dematerialization
Equally Lethargic JSON Support for iOS/macOS, Part 4: Our Keys are Small but Legion
Less Lethargic JSON Support for iOS/macOS, Part 5: Cutting out the Middleman
Somewhat Faster JSON Support for iOS/macOS, Part 6: Cutting KVC out of the Loop
Faster JSON Support for iOS/macOS, Part 7: Polishing the Parser
Faster JSON Support for iOS/macOS, Part 8: Dematerialize All the Things!
Beyond Faster JSON Support for iOS/macOS, Part 9: CSV and SQLite

1 comment:
I mentioned your post in my recent Boost.JSON review. I thought you would be interested as it's a subject you enjoy: https://gitlab.com/-/snippets/2016550
Post a Comment