By popular demand, a quick rundown of
MPWTest (“
The Simplest Testing Framework That Could Possibly Work”), my own personal unit testing framework, and
how it makes TDD fast, fun, and frictionless.
I created MPWTest because once I had been bitten by the TDD bug, I definitely did not
want to write software without TDD ever again, if I could help it. This was long before XCTest, and even its
precursor SenTestKit was in at best in parallel development, I certainly
wasn't aware of it.
It is a bit different, and the differences make it sufficiently better that I
much prefer it to the xUnit variants that I've worked with (JUnit, some SUnit, XCTest). All of these are
vastly better than not doing TDD, but they introduce significant amounts of
overhead, friction, that make the testing experience much more cumbersome
than it needs to be, and to me at least partly explains some of the antipathy
I see towards unit testing from developers.
The attitude I see is that testing is like eating your vegetables, you know
it's supposed to be good for you and you do it, grudgingly, but it really
is rather annoying and the benefits are more something you know intellectually.
For me with MPWTest, TDD is also still intellectually a Good Thing™, but also
viscerally fun, less like vegetables and more like tasty snacks, except
that those snacks are not just yummy, but also healthy. It helps me stay in
the flow and get things done.
What it does is let me change code quickly and safely, the key to agile:
Here is how it works.
Setup
First you need to build the
testlogger binary of the
MPWTest project. I put mine in
/usr/local/bin and forget about it. You can put it anywhere you like, but will have to adjust the paths
in what follows.
Next, add a "Script" build phase to your (framework) project. MPWTest currently only
tests frameworks.
tester=/usr/local/bin/testlogger
framework=${TARGET_BUILD_DIR}/${FULL_PRODUCT_NAME}
if [ -f ${tester} ] ; then
$tester ${framework}
else
echo "projectfile:0:1: warning: $tester or $framework not found, tests not run"
fi
The bottom of the Build Phases pane of your project should then look something roughly like the following:
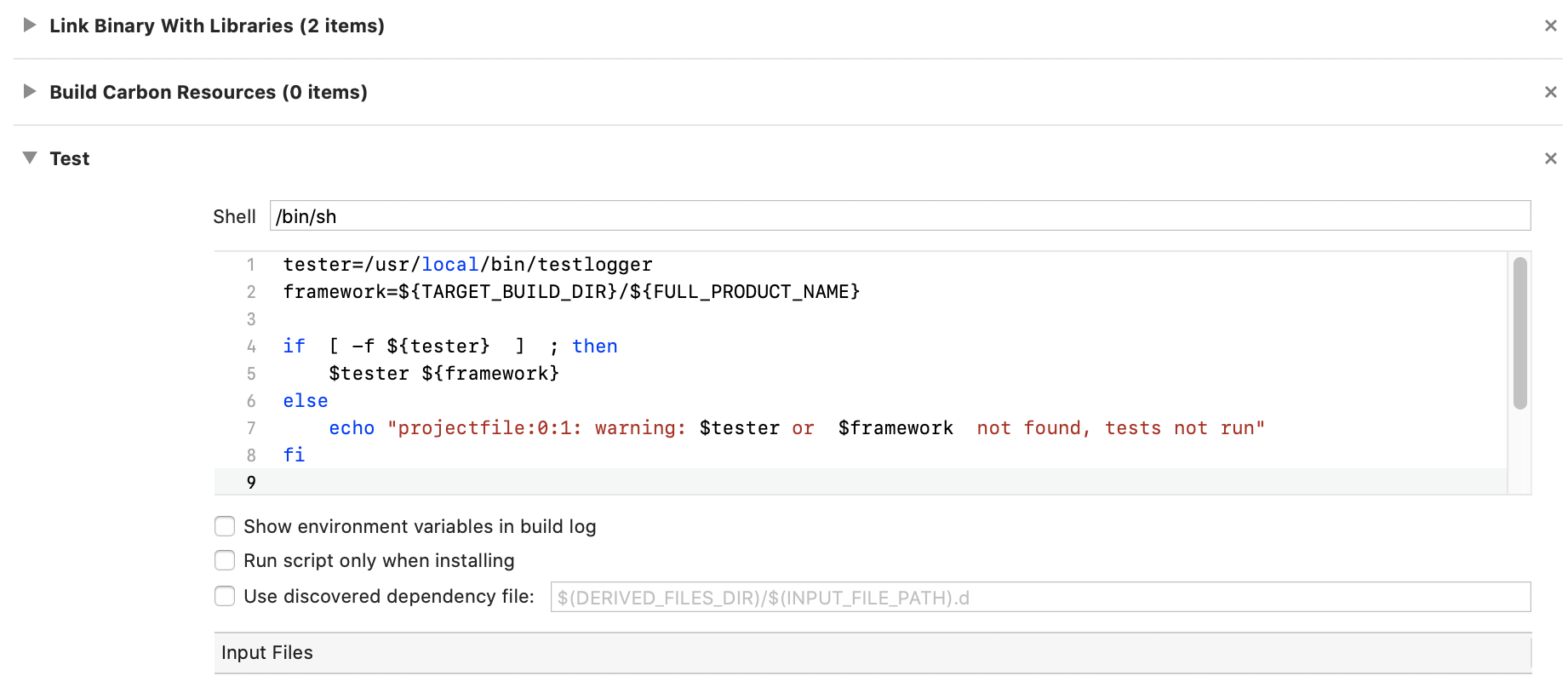
There is no separate test bundle, no extra targets, nada. This may not seem such
a big deal when you have just a single target, but once you start getting having
a few frameworks, having an additional test target for each really starts to
add up. And adds a decision-point: should I really create an additional
test bundle for this project? Maybe I can just repurpose this existing one?
Code
In the class to be tested, add the
+(NSArray*)testSelectors method,
returning the list of tests to run/test methods to execute. Here is an example
from the JSON parser I've been writing about:
+testSelectors
{
return @[
@"testParseJSONString",
@"testParseSimpleJSONDict",
@"testParseSimpleJSONArray",
@"testParseLiterals",
@"testParseNumbers",
@"testParseGlossaryToDict",
@"testDictAfterNumber",
@"testEmptyElements",
@"testStringEscapes",
@"testUnicodeEscapes",
@"testCommonStrings",
@"testSpaceBeforeColon",
];
}
You could also determine these names automagically, but I prefer the explicit list
as part of the specification: these are the tests that should be run.
Otherwise it is too easy to just lose a test to editing mistakes and be
none the wiser for it.
Then just implement a test, for example testUnicodeEscapes:
+(void)testUnicodeEscapes
{
MPWMASONParser *parser=[MPWMASONParser parser];
NSData *json=[self frameworkResource:@"unicodeescapes" category:@"json"];
NSArray *array=[parser parsedData:json];
NSString *first = [array objectAtIndex:0];
INTEXPECT([first length],1,@"length of parsed unicode escaped string");
INTEXPECT([first characterAtIndex:0], 0x1234, @"expected value");
IDEXPECT([array objectAtIndex:1], @"\n", @"second is newline");
}
Yes, this is mostly old code. The macros do what you, er, expect:
INTEXPECT() expects integer equality (or other scalars, to be honest),
IDEXPECT() expects object equality. There are
also some conveniences for nil, not nil, true and false, as well as a specialized one
for floats that sets an acceptable range.
In theory, you can put these methods anywhere, but I tend to place them in a
testing category at the bottom of the file.
...
@end
#import "DebugMacros.h"
@implementation MPWMASONParser(testing)
The
DebugMacros.h header has the various
EXPCECT() macros.
The header is the only dependency in your code, you do not need to link anything.
Even more than not having a separate test bundle, not having a separate test class
(-hierarchy) really simplifies things. A lot.
First, there is no question as to where to find the tests for a particular class:
at the bottom of the file, just scroll down. Same for the class for some tests:
scroll up. I find this incredibly useful, because the tests serve as specification,
documentation and example code for class.
There is also no need to maintain parallel class hierarchies, which are widely
regarded as a fairly serious code-smell, for the obvious reasons: the need to keep those hierarchies in sync along
with the problems once they do get out of sync, which they will, etc.
Use
After the setup, you just build your projects, the tests will be run automatically
as part of the build. If there are test failures, they are reported by Xcode
as you would expect:
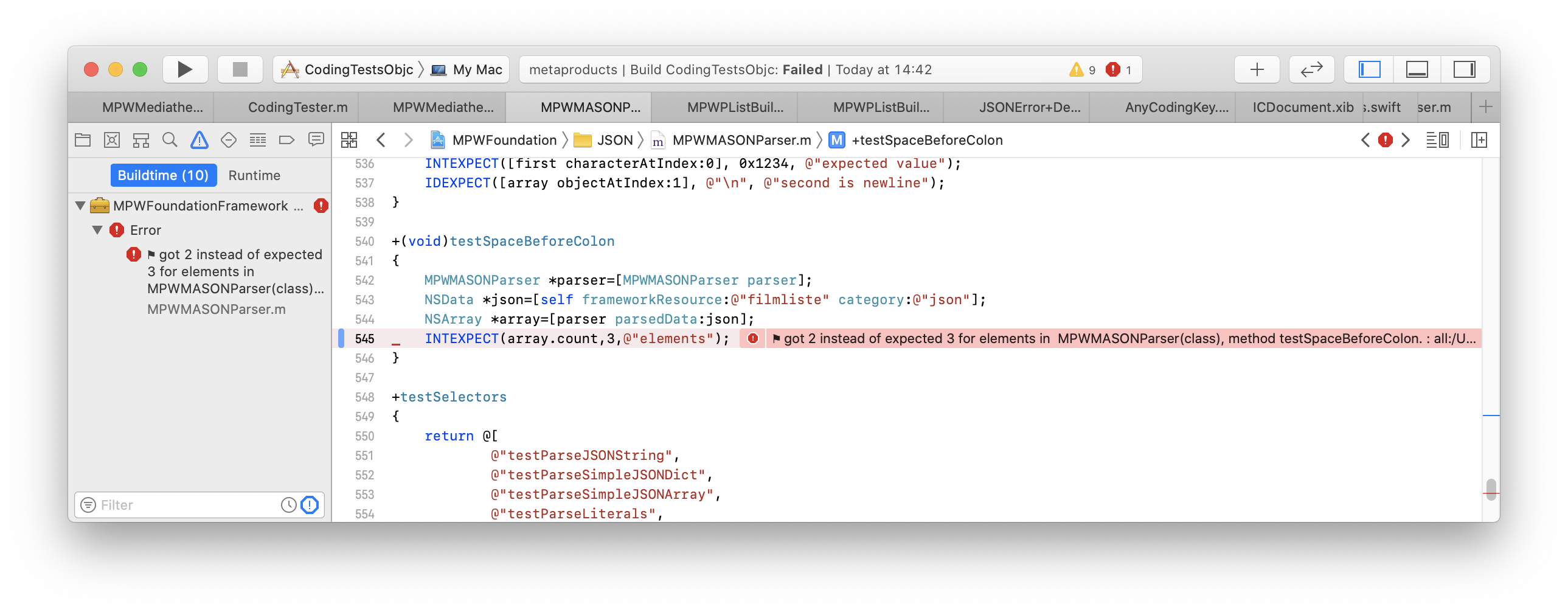
My steps tend to be:
- add name of test to
+testSelectors,
- hit build to ensure tests are red,
- while Xcode builds, add empty test method,
- hit build again to ensure tests are now green,
- either add an actual
EXPECT() for the test,
- or an
EXPECTTRUE(false,@"impelemented") as placeholder
This may seem like a lot of steps, but it's really mostly just letting
Xcode check things while I am doing the edits that need to be done
anyhow. Hitting Cmd-B a couple of times while editing doesn't hurt.
The fact that tests run as part of every build, because you cannot
build without running the tests, gives you a completely different
level of confidence in your code, which translates to courage.
Running the tests all the time is also splendid motivation to keep those
tests green, because if the tests fail, the build fails. And if the
build fails, you cannot run the program. Last not least, running the
tests on every build also is strong motivation to keep those tests
fast. Testing just isn't this separate activity, it's as integral
a part of the development process as writing code and compiling it.
Caveats
There are some drawbacks to this approach, one that the pretty Xcode
unit test integration doesn't work, as when this was done Apple had
already left the platform idea behind and was only focused on making
an integrated solution.
As noted above, displaying test failures as errors and jumping to the
line of the failed test-expectation does work. This hooks
into the mechanism Xcode uses to get that information from compilers,
which simply output the line number and error message on stdout.
Any tool that formats its output the same way will work wth Xcode.
In the end, while I do enojoy the blinkenlights of Xcode's unit test
integration, and being able to run tests individually with simple
mouse-click, all this bling really just reinforces that idea of
tests as a separate entity. If my tests are always run and
are always green, and are always fast, then I don't need or
even want UI for them, the UI is a distraction, the tests
should fade into the background.
Another slightly more annoying issue is debugging: as the tests are run
as part of the build, a test failure is a build failure and will
block any executables from running. However, Xcode only debugs
executables, so you can't actually get to a debuggable run session.
As I don't use debuggers all that much, and failure in TDD usually
manifests itself in test failure rather than something you need the
debugger to track, this hasn't been much of a problem. In the past,
I would then just revert to the command line, for example with
lldb testlogger MPWFoundation to debug my foundation framework,
as you can't actually run a framewework.
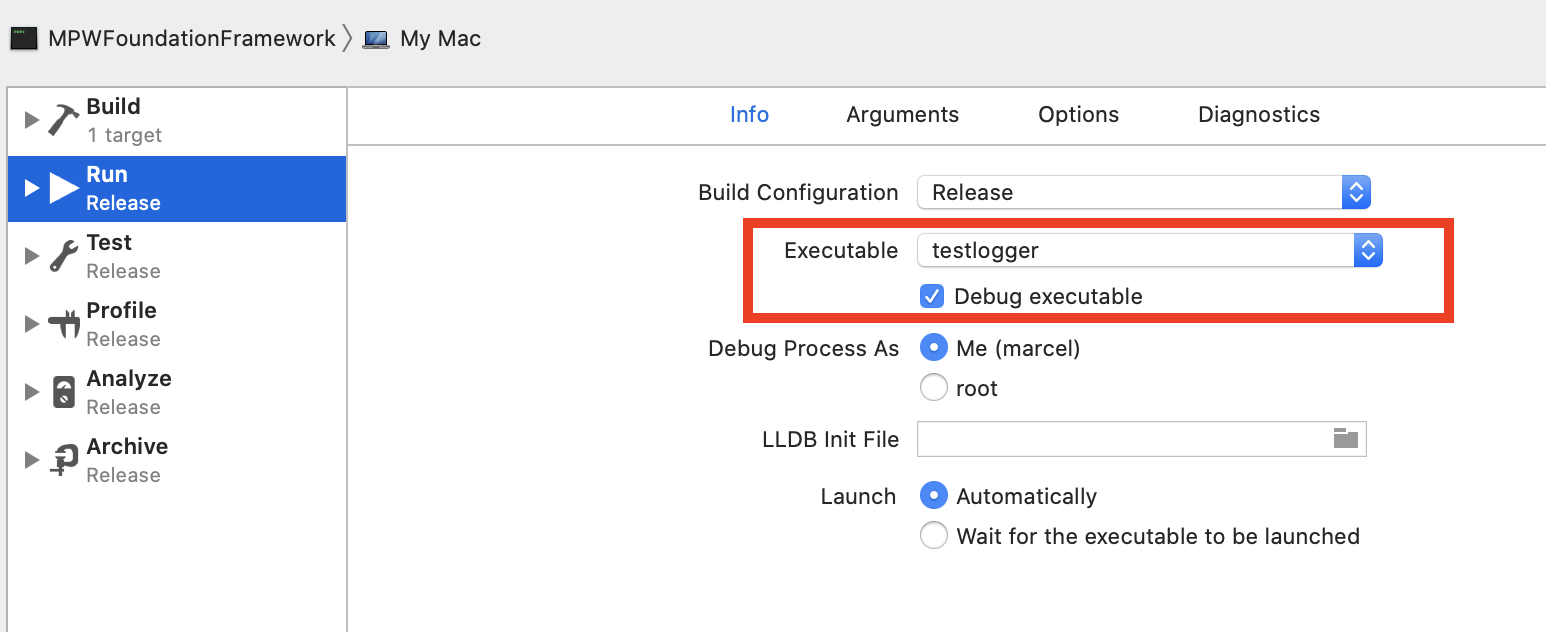
Or so I thought. Only receently
did I find out that you can set an executable parameter in your target's
build scheme. I now set that to testlogger and can debug the
framework to my heart's content.
Leaving the problem of Xcode not actually letting me run the executable due to
the build failing, and as far as I know having no facility for debugging
build phases.
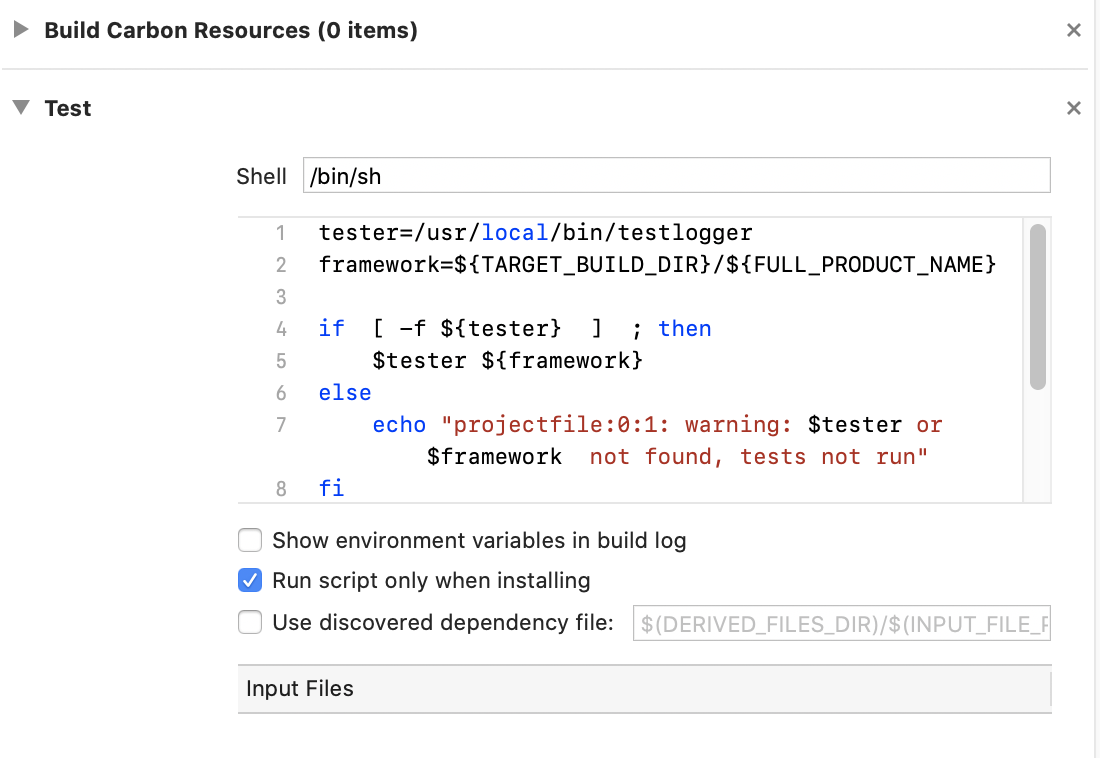
The workaround for that is temporarily disabling the Test build phase,
which can be accomplished by misusing the "Run script only when installing" flag.
While these issues aren't actually all the significant, they are somewhat more
jarring than you might expect because the experience is so buttery smooth the
rest of the time.
Of course, if you want a pure test class, you can do that: just create a
class that only has tests. Furthermore, each class is actually asked for
a test fixture object for each test. The default is just to return the
class object itself, but you can also return an instance, which can have
setup and teardown methods the way you expect from xUnit.
The code to enumerate and probe all classes in the system in order to find
tests is also interesting, if straightforward, and needs to be updated from
time to time, as there are a few class in the system that do not like to be probed.
Outlook
I'd obviously be happy if people try out MPWTest and find it useful. Or find
it not so useful and provide good feedback. I currently have no specific
plans for Swift support. Objective-C compatible classes should probably work,
the rest of the language probably isn't dynamic enough to support this kind
of transparent integration, certainly not without more compiler work.
But I am currently investigating Swift interop. more generally, and now
that I am no longer restricted to C/Objective-C, more might be possible.
I will almost certainly use the lessons learned here to create linguistically
integrated testing in Objective-Smalltalk. As with many other aspects of
Objective-Smalltalk, the gap to be bridged for super-smooth is actually not
that large.
Another takeaway is that unit testing is really, really simple. In fact,
when I asked Kent Beck about it, his response was that everyone should
build their own. So go and build wonderful things!


{kind=link}