My post from last year titled The Siren Call of KVO and Cocoa Bindings has been one of my
most consequential so far. Apart from being widely circulated and discussed, it has also been a
focal point of my ongoing work related to Objective-Smalltalk.
The ideas presented there have been central to my talksonsoftwarearchitecture, and I have
finally been able to present some early results I find very promising.
Alas, with the good always comes the bad, and some of the reactions (sic) have no been quite so
positive. For example, consider the following I wrote:
[..] Adding reactivity to an object-oriented language is, at first blush, non-sensical and certainly causes confusion [because] whereas functional programming, which is per definition static/timeless/non-reactive, really needs something to become interactive, reactivity is already inherent in OO. In fact, reactivity is the quintessence of objects: all computation is modeled as objects reacting to messages.
This seemed quite innocuous, obvious, and completely uncontroversial to me,
but apparently caused a bit of a stir with at least some of the creators of ReactiveCocoa:
@Javi@kyleve lol, that’s the guy who said “OO is already reactive, so who needs FRP”
Ouch! Of course I never wrote that "nobody" needs FRP: Functional Programming definitely needs
FRP or something like it, because it isn't already reactive like objects are. Second, what I wrote is
that this is non-sensical "at first blush" (so "on first impression"). Idiomatically, this phrase is usually sets up a "
...but on closer examination", and lo-and-behold, almost the entire rest of the post
talks about how the related concepts of dataflow and dataflow-constraints are highly desirable.
The point was and is (obviously?) a
terminological one, because the existing term "reactivity" is being overloaded
so much that it confuses more than it clarifies. And quite frankly, the idea
of objects being "reactive" is (a) so self-evident (you send a message, the object reacts
by executing method which usually sends more messages) and (b) so deeply ingrained and
basic that I didn't really think about it much at all. So obviously, it could very
well be that I was wrong and that this was "common sense" to me in the Einsteinian
sense.
I will explore the terminological
confusion more in later posts, but suffice it to say that Conal Elliott contacted
the ReactiveCocoa guys to tell them (politely) that whatever ReactiveCocoa was, it certainly wasn't FRP:
I'm hoping to better understand how the term "Functional Reactive Programming" gets applied to systems that are so far from the original definition and principles (continuous time with precise & simple mathematical meaning)
A group of leading experts from industry and academia came together last fall at the invitation of IBM and ACM to ponder the primary areas of future needs in software support for object-based applications.
[..]
In the future, as you talk about having an economy based on these entities (whether we call them “objects” or we call them something else), they’re going to have to be more proactive. Whether they’re intelligent agents or subjective objects, you enable them with some responsibility and they get something done for you. That’s a different view than we have currently where objects are reactive; you send it a message and it does something and sends something back.
But lol, that's only a group of leading researchers invited by IBM and the ACM writing in
arguably one of the most prestigious computing publications, so what do they know?
Let's see what the Blue Book from 1983 has to say when defining what objects are:
The set of messages to which an object can respond is called its interface with the rest of the system. The only way to interact with an object is through its interface. A crucial property of an object is that its private memory can be manipulated only by its own operations. A crucial property of messages is that they are the only way to invoke an object's operations. These properties insure that the implementation of one object cannot depend on the internal details of other objects, only on the messages to which they respond.
So the crucial definition of objects according the creators of Smalltalk is that they respond
to messages. And of course if you check a dictionary or thesaurus, you will find that respond
and react are synonyms. So the fundamental definition of objects is that they react to messages.
Hmm...that sounds familiar somehow.
While those are seemingly pretty influential definitions, maybe they are uncommon? No.
A simple google search reveals that this definition is extremely common, and has been
around for at least the last 30-40 years:
A conventional statement of this principle is that a program should never declare that a given object is a SmallInteger or a LargeInteger, but only that it responds to integer protocol.
But lol, what do Adele Goldberg, David Robson or Dan Ingalls know about Object Oriented
Programming? After all, we have one of the creators of ReactiveCocoa here!
(Funny aside: LinkedIn once asked me "Does Dan Ingalls know about Object Oriented
Programming?" Alas there wasn't a "Are you kidding me?" button, so I lamely clicked "Yes").
Or maybe it's only those crazy dynamic typing folks that no-one takes seriously these days? No.
So the only thing relevant thing for typing purposes is how an object
reacts to messages.
Here's a section from the Haiku/BeOS documentation:
The draw object reacts to messages from the panel, thereby creating an IT
to cover the canvas.
CS lecture on OO:
Properties implemented as "fields" or "instance variables"
constitute the "state" of the object
affect how object reacts to messages
Heck, even the Apple Cocoa/Objective-C docs speak of "objects responding to messages", it's
almost like a conspiracy.
By separating the message (the requested behavior) from the receiver (the owner of a method that can respond to the request), the messaging metaphor perfectly captures the idea that behaviors can be abstracted away from their particular implementations.
Book on OO Analysis and Design:
As the object structures are identified and modeled, basic processing
requirements for each object can be identified. How each object
responds to messages from other objects needs to be defined.
An object's behavior is defined by its message-handlers(handlers). A message-handler for an object responds to messages and performs the required actions.
Or maybe this is an old definition from the 80ies and early 90ies that has fallen out of use? No.
The behavior of related collections of objects is often defined by a class,
which specifies the state variables of an objects (its instance variables)
and how an object responds to messages (its instance methods).
Methods: Code blocks that define how an object responds to messages.
Optionally, methods can take parameters and generate return values.
The main difference between the State Machine and the immutable is the way the object reacts to messages being sent (via methods invoked on the public interface). Whereas the State Machine changes its own state, the Immutable creates a new object of its own class that has the new state and returns it.
So to sum up: classic OOP is definitely reactive. FRP is not, at least according to the guy
who invented it. And what exactly things like ReactiveCocoa and Elm etc. are, I don't think
anyone really knows, except that they are not even FRP, which wasn't, in the end reactive.
Tune in for "What the Heck is Reactive Programming, Anyway?"
Early last year, I wrote a lengthy piece on the connection between Apple
technologies such as Key Value Observing (KVO) and Bindings and general
Computer Science concepts such as constraint solving, particularly
dataflow constraints (aka. Spreadsheet Constraints).
I also wrote that I was working on something, and despite being somewhat
distracted with becoming a father, joining a startup and being acquired,
I now have working code.
The sample application contains two examples, one a classic temperature
converter that I will cover later, the other an implementation of the
ReactiveCocoa password validation example. The basic
idea is super-simple, we want to enable a login button when the password
field and the confirmation field contain the same value, expressed as
follows in Objective-C:
Again, this is super simple to write down, but it's not the entire story, because
we want to evaluate this statement continuously as the password field and the
passwordConfirm field change. The mess of callbacks require to keep those
states in sync vastly exceeds the one-time evaluation, as explained in
a very good article on Reactive
Cocoa by NSHipster. That article uses a slightly more elaborate example, the
one in the ReactiveCocoa documentation is the following:
What's noticeable, apart from the macros that are necessary, is the semantic noise apparently inherent in this solution. Instead
of focusing on what we want to accomplish (hidden inside the last return),
the focus is on generic RAC classes such as RACSignal and methods
such as combineLatest: and reduce:. I didn't really
want to combine and reduce, I just wanted to keep some different states in sync,
and with Objective-Smalltalk, I can do just that.
Let's first recast the original Objective-C expression into Objective-Smalltalk.
Since Smalltalk is not burdened by the syntactic legacy of C, we can lose the square
brackets. Because we have binary selectors (a bit like operators) and use ':=' for
assignment, we can use '=' to check for equality instead of having to write out
'isEqual:'. The dots get replaced by slashes because Polymorphic Identifiers use
URI syntax, and finally we use periods instead of semicolons at the end of sentences,
er, statements.
Again, this is semantically the same statement as the original Objective-C, it
assigns the right hand side to the left hand side. This can be viewed as a
a one way constraint: the left hand side should be the same as the right hand side.
The constraint has a fundamental flaw, though, because it is only maintained
instantaneously as the line of code is executed. After that, left hand side
and right hand side can diverge again. What we want is for that constraint
to be maintained indefinitely: whenever the right hand side changes, the
left hand side should be updated. In Objective-Smalltalk, you can now
express this by replacing the ":=" assignment operator (technically: connector),
with the "|=" constraint connector:
I probably should have taken more notice that time that after my question about why a specific piece
of the UI code had been structured in a particular way,
one of my colleagues at 6wunderkinder informed
me that Model View Controller meant the View must not talk to the model, and instead the Controller
is responsible for mediating all interaction between the View and the Model. It certainly didn't
match the definition of MVC that I knew, so I checked the Wikipedia page on MVC just in case I had gone
completely senile, but it checked out with that I remembered:
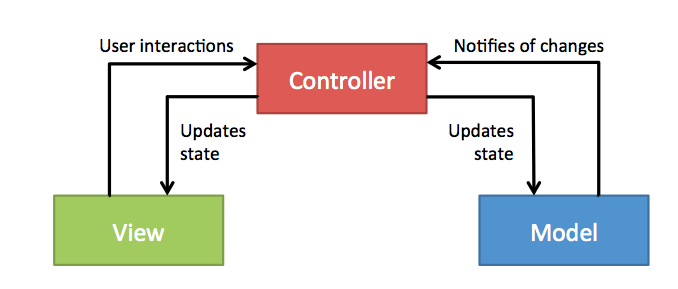
the controller updates the model,
the model notifies the view that it has changed, and finally
the view updates itself by talking to the model
(The labeling on the graphic on the Wikipedia is a bit misleading, as it suggests that the model updates
the view, but the text is correct).
What I should have done, of course, is keep asking "Why?", but I didn't, my excuse being that we were
under pressure to get the Wunderlist 3.0 release out the door. Anyway, I later followed up some of
my confusion about both React.native and ReactiveCocoa (more on those in a later post) and found the
following incorrect diagram in a Ray Wenderlich tutorial on ReactiveCocooa and MVVC.
Hmm...that's the same confusion that my colleague had. The plot thickens as I re-check Wikipedia just
to be sure. Then I had a look at the original MVC papers by Trygve Reenskaug, and yes:
A view is a (visual) representation of its model. It would ordinarily highlight certain attributes of the model and suppress others. It is thus acting as a presentation filter.
A view is attached to its model (or model part) and gets the data necessary for the presentation from the model by asking questions.
The 1988 JOOP article "MVC Cookbook" also confirms:
So where is this incorrect version of MVC coming from? It turns out, it's in the Apple documentation, in the overview section!
I have to admit that I hadn't looked at this at least in a while, maybe ever, so you can imagine my surprise
and shock when I stumbled upon it. As far as I can tell, this architectural style comes from having
self-contained widgets that encapsulate very small pieces of information such as simple strings, booleans
or numbers. The MVC architecture was not intended for these kinds of small widgets:
MVC was conceived as a general solution to the problem of users controlling a large and complex data set.
If you look at the examples, the views are large both in size and in scope, and they talk to a complex model.
With a widget, there is no complex model, not filtering being done by the view. The widget contains its own
data, for example a string or a number. An advantage of widgets is that you can meaningfully assemble them in a tool like Interface Builder, with a more MVC-like large view, all you have in IB is a large blank space labeled
'Custom View'. On the other hand, I've had very good experiences with "real" (large view) MVC in creating
high performance, highly responsive user interfaces.
Model Widget Controller (MWC) as I like to call it, is more tuned for forms and database programming, and
has problems with more reactive scenarios. As Josh Abernathy wrote:
Right now we write UIs by poking at them, manually mutating their properties when something changes, adding and removing views, etc. This is fragile and error-prone. Some tools exist to lessen the pain, but they can only go so far. UIs are big, messy, mutable, stateful bags of sadness.
To me, this sadness is almost entirely a result of using MWC rather than MVC. In MVC, the "V" is
essentially a function of the model, you don't push or poke at it, you just tell it "something changed" and
it redraws itself.
And so the question looms: is react.native just a result of (Apple's) misunderstanding (of) MVC?
As always, your comments are welcome here or on HN.
I like bindings. I also like Key Value Observing. What they do is undeniably cool: you do some initial setup, and presto: magic! You change a value over here, and another
value over there changes as well. Action at a distance. Power.
What they do is also undeniably valuable. I'd venture that nobody actually
likes writing state
maintenance and update code such as the following: when the user clicks this button, or finishes entering
text in that textfield, take the value and put it over here. If the underlying
value changes, update the textfield. If I modify this value, notify
these clients that the value has changed so they can update themselves accordingly.
That's boring. There is no glory in state maintenance code, just potential for
failure when you screw up something this simple.
Finally, their implementation is also undeniably cool: observing an attribute
of a generic
object creates a private subclass for that object (who says we can't do
prototype-based programming in Objective-C?), swizzles the object's
class pointer to that private subclass and then replaces the attribute's
(KVO-compliant) accessor methods with new ones that hook into the
KVO system.
Despite these positives, I have actively removed bindings code from
projects I have worked on, don't use either KVO or bindings myself and
generally recommend staying away from them. Why on earth would I
do that?
Excursion: Constraint Solvers
Before I can answer that question, I have to go back a little and talk about
constraint solvers.
The idea of setting up relationships once and then having the system maintain them
without manually shoveling values back and forth is not exactly new, the first variant
I am aware of was Sketchpad,
Ivan Sutherland's PhD Thesis from 1961/63 (here with narration by Alan Kay):
I still love Ivan's answer to the question as to how he could invent computer graphics,
object orientation and constraint solving in one fell swoop: "I didn't know it was hard".
The first system I am aware of that integrated constraint solving with an object-oriented
programming language was ThingLab, implemented on top of Smalltalk by Alan Borning at Xerox PARC around 1978 (where else...):
While the definition
of a paths is simple, the idea behind it has proved quite powerful and has been essential
in allowing constraint- and object-oriented metaphors to be integrated. [..] The notion
of a path helps strengthen [the distinction between inside and outside of an object] by
providing a protected way for an object to provide external reference to its parts and
subparts.
Yes, that's a better version of KVC. From 1981.
Alan Borning's group at the University of Washington continued working on constraint solvers
for many years, with the final result being the Cassowary linear constraint solver (based on the simplex
algorithm) that was picked up by Apple for Autolayout. The papers on Cassowary and
constraint hierarchies should help with understanding why Autolayout does what it does.
A simpler form of constraints are one-way dataflow constraints.
A one-way, dataflow constraint is an equation of the form y = f(x1,...,xn) in which the formula on the right side
is automatically re-evaluated and assigned to the variable y whenever any variable xi.
If y is modified from
outside the constraint, the equation is left temporarily unsatisfied, hence the attribute “one-way”. Dataflow constraints are recognized as a powerful programming methodology in a variety of contexts because of their versatility and simplicity. The most widespread application of dataflow constraints is perhaps embodied by spreadsheets.
The most important lessons they found were the following:
constraints should be allowed to contain arbitrary code that is written in the underlying toolkit language and does not require any annotations, such as parameter declarations
constraints are difficult to debug and better debugging tools are needed
programmers will readily use one-way constraints to specify the graphical layout of an application, but must be carefully and time-consumingly trained to use them for other purposes.
However, these really are just the headlines, and particularly for Cocoa programmers
the actual reports are well worth reading as they contain many useful pieces of
information that aren't included in the summaries.
Back to KVO and Cocoa Bindings
So what does this history lesson about constraint programming have to do with KVO
and Bindings? You probably already figured it out: bindings are one-way
dataflow constraints, specifically with the equation limited to y = x1.
more complex equations can be obtained by using NSValueTransformers. KVO
is more of an implicit invocation
mechanism that is used primarily to build ad-hoc dataflow constraints.
The specific problems of the API and the implementation have been documented
elsewhere, for example by Soroush Khanlou and Mike Ash, who not only suggested and
implemented improvements back in 2008, but even followed up on them in 2012. All
these problems and workarounds
demonstrate that KVO and Bindings are very sophisticated, complex and error prone
technologies for solving what is a simple and straightforward task: keeping
data in sync.
To these implementation problems, I would add performance: even
just adding the willChangeValueForKey: and didChangeValueForKey:
message sends in your setter (these are usually added automagically for you) without triggering any notifications makes that setter 30 times slower (from 5ns to
150ns on my computer) than a simple setter that just sets and retains the object.
Actually having that access trigger a notification takes the penalty to a factor of over 100
( 5ns vs over 540ns), even when there is only a single observer. I am pretty sure
it gets worse when there are lots of observers (there used to be an O(n^3)
algorithm in there, that was fortunately fixed a while ago). While 500ns may
not seem a lot when dealing with UI code, KVO tends to be implemented at
the model layer in such a way that a significant number of model data accesses
incur at least the base penalties. For example KVO notifications were one of the primary
reasons for NSOperationQueue's somewhat anemic performance back when
we measured it for the Leopard release.
Not only is the constraint graph not available at run time, there is also no
direct representation at coding time. All there is either code or IB settings
that construct such a graph indirectly, so the programmer has to infer the
graph from what is there and keep it in her head. There are also no formulae, the best
we can do are ValueTransformers and
keyPathsForValuesAffectingValueForKey.
As best as I can tell, the reason for this state of affairs is that there simply
wasn't any awareness of the decades of
research and practical experience with constraint solvers at the time (How
do I know? I asked, the answer was "Huh?").
Anyway, when you add it all up, my conclusion is that while I would really,
really, really like a good constraint solving system (at least for spreadsheet
constraints), KVO and Bindings are not it. They are too simplistic, too
fragile and solve too little of the actual problem to be worth the trouble.
It is easier to just write that damn state maintenance code, and infinitely
easier to debug it.
I think one of the main communication problems between advocates for and
critics of KVO/Bindings is that the advocates are advocating more for
the concept of constraint solving, whereas critics are critical of the
implementation. How can these critics not see that despite a few flaws,
this approach is obviously
The Right Thing™? How can the advocates not see the
obvious flaws?
Functional Reactive Programming
As far as I can tell, Functional Reactive Programming (FRP) in general and Reactive
Cocoa in particular are another way of scratching the same itch.
[..] is an integration of declarative [..] and imperative object-oriented programming. The primary goal of this integration is to use constraints to express relations among objects explicitly -- relations that were implicit in the code in previous languages.
Sounds like FRP, right? Well, the first "[..]" part is actually "Constraint Imperative Programming" and the second is "constraints",
from the abstract of a 1994 paper. Similarly, I've seen it stated that FRP is like a spreadsheet.
The connection between functional programming and constraint programming is also well
known and documented in the literature, for example the experience report above states the
following:
Since constraints are simply functional programming dressed up with syntactic sugar, it should not be surprising that 1) programmers do not think of using constraints for most programming tasks and, 2) programmers require extensive training to overcome their procedural instincts so that they will use constraints.
However, you wouldn't be able to tell that there's a relationship there from reading
the FRP literature, which focuses exclusively on the connection to functional
programming via functional reactive animations and Microsoft's Rx extensions. Explaining and particularly motivating FRP this way has the
fundamental problem that whereas functional programming, which is per definition
static/timeless/non-reactive, really needs something to become interactive,
reactivity is already inherent in OO. In fact, reactivity is the quintessence of
objects: all computation is modeled as objects reacting to messages.
So adding reactivity to an object-oriented language is, at first blush, non-sensical
and certainly causesconfusion when explained this way.
I was certainly confused, because until I found this one
paper on reactive imperative programming,
which adds constraints to C++ in a very cool and general way,
none of the documentation, references or papers made the connection that seemed so
blindingly obvious to me. I was starting to question my own sanity.
Architecture
Additionally, one-way dataflow constraints creating relationships between program variables
can, as far as I can tell, always be replaced by a formulation where the dependent
variable is simply replaced by a method that computes the value on-demand. So
instead of setting up a constraint between point1.x and point2.x,
you implement point2.x as a method that uses point1.x to
compute its value and never stores that value. Although this may evaluate more
often than necessary rather than memoizing the value and computing just once, the
additional cost of managing constraint evaluation is such that the two probably
balance.
However, such an implementation creates permanent coupling and requires dedicated
classes for each relationship. Constraints thus become more of an architectural
feature, allowing existing, usually stateful components to be used together without
having to adapt each component for each individual ensemble it is a part of.
Panta Rhei
Everything flows, so they say. As far as I can tell, two different
communities, the F(R)P people and the OO people came up with very similar
solutions based on data flow. The FP people wanted to become more reactive/interactive,
and achieved this by modeling time as sequence numbers in streams of values, sort
of like Lucid or other dataflow languages.
The OO people wanted to be able to specify relationships declaratively and have
their system figure out the best way to satisfy those constraints, with
a large and useful subset of those constraints falling into the category of
the one-way dataflow constraints that, at least to my eye, are equivalent
to FRP. In fact, this sort of state maintenance and update-propagation
pops up in lots of different places, for example makefiles or other
build systems, web-server generators, publication workflows etc. ("this
OmniGraffle diagram embedded as a PDF into this LaTeX document that
in turn becomes a PDF document" -> the final PDF should update
automatically when I change the diagram, instead of me having to
save the diagram, export it to PDF and then re-run LaTeX).
What's kind of funny is that these two groups seem to have converged
in essentially the same space, but they seem to not be aware of
each other, maybe they are phase-shifted with respect to each other?
Part of that phase-shift is, again, communication. The FP guys
couch everything in must destroy all humans er state rethoric,
which doesn't do much to convince OO guys who know that for most
of their programs, state isn't an implementation detail but fundamental
to their applications. Also practical experience does not support the
idea that the FP approach is obvious:
Unfortunately, given the considerable amount of time required to train students to use constraints in a non-graphical manner, it does not seem reasonable to expect that constraints will ever be widely used for purposes other than graphical layout. In retrospect this result should not have been surprising. Business people readily use constraints in spreadsheets because constraints match their mental model of the world. Similarly, we have found that students readily use constraints for graphical layout since constraints match their mental model of the world, both because they use constraints, such as left align or center, to align objects in drawing editors, and because they use constraints to specify the layout of objects in precision paper sketches, such as blueprints. However, in their everyday lives, students are much more accustomed to accomplishing tasks using an imperative set of actions rather than using a declarative set of actions.
Of course there are other groups hanging out in this convergence zone, for example the
Unix folk with their pipes and filters. That is also not too surprising if
you look at the history:
So, we were all ready. Because it was so easy to compose processes with shell scripts. We were already doing that. But, when you have to decorate or invent the name of intermediate files and every function has to say put your file there. And the next one say get your input from there. The clarity of composition of function, which you perceived in your mind when you wrote the program, is lost in the program. Whereas the piping symbol keeps it. It's the old thing about notations are important.
I think the familiarity with Unix pipes also increases the itch: why can't I have
that sort of thing in my general purpose programming language? Especially when
it can lead to very concise programs, such as the Quartz-like graphics subsystem
Gezira written in
under 400 lines of code using the Nile dataflow language.
Moving Forward
I too have heard the siren sing.
I also think that a more spreadsheet-like programming model would not just make my life
as a developer easier, it might also make software more approachable for end-user adaptation and tinkering,
contributing to a more meaningful version of open source. But how do we get there?
Apart from a reasonable implementation and better debuggingsupport, a new system would need much tighter
language integration. Preferably there would be a direct syntax for expressing constraints
such as that available in constraint imperative programming languages or constraint extensions to existing
languages like
Ruby or JavaScript.
This language support should be unified as much as
possible between different constraint systems, not one mechanism for Autolayout and a
completely different one for Bindings.
Supporting constraint programming has always been one of the goals of my Objective-Smalltalk project, and so far that has informed the
PolymorphicIdentifiers that support a uniform interface for data backed by different types of
stores, including one or more constraint stores supporting cooperating solvers, filesystems or web-sites. More needs
to be done, such as extending the data-flow connector hierarchy to conceptually integrate
constraints. The idea is to create a language that does not actually include constraints
in its core, but rather provides sufficient conceptual, expressive and implementation
flexibility to allow users to add such a facility in a non-ad-hoc way so that it is
fully integrated into the language once added. I am not there yet, but all the results
so far are very promising. The architectural focus of Objective-Smalltalk also ties
in well with the architectural interpretation of constraints.
There is a lot to do, but on the other hand I think the payback is huge, and there is
also a large body of existing theoretical,
practical and empirical groundwork to fall back on, so I think the task is doable.
Your feedback, help and pull requests would be very much appreciated!